Introduction
aider is an LLM based tool you can run on your command line and ask it to write code for you.
It’s similar to tools like Cursor and Copilot X, in that you can ask it to make changes to your code and build new features and it can do so.
However, it has a few nice tricks that it can do which make it a little more useful:
- You can script it, so you can use it as part of automation or more complex scripts.
- It builds a repo map of your repository so that it can have contextual awareness of your codebase, even without any files added to the context.
These two points will be very useful for our specific use case.
At MeetsMore, we have some legacy codebases that have strict mode disabled in TypeScript, because they used to be JavaScript codebases many years ago that were then migrated to TypeScript.
We really want to enable it, but we have something like 10,000~ tsc errors when we enable it.
This isn’t really feasible to fix by hand, and the errors are mostly very easy to fix one-by-one, so we turned to aider to help.
aider is nice, but one of the issues of asking an LLM to do such a big refactor is the cost, we would be putting far too many tokens into aider if we added all of the code we’d like to add to fix our TS problems, and this would be a huge cost, and also beyond most context windows of many LLMs.
So we built a little scripting tool that takes a tsc output as its input, and it groups all of the errors by file, and allows you to select which files and errors you want to fix.

For each file, this then invokes aider , asking it to fix the errors in the file.
We’re using Claude Haiku for this, and it results in a cost of less than $0.05c per file.
On our test repositories, it worked great, but when we tried it on our monorepo, it wasn’t working at all. 😟
So we investigated a little, and discovered the issue is with the aider repo map.
Repo Map
You should read Paul’s description of the aider repo map yourself, but here is a quick explanation of what it does:
- Goes through all files in your codebase and collects all symbols (functions, constants, etc).
- Creates a graph of all symbols and files and how closely related they are using the Pagerank algorithm.
- Sorts the symbols by the most relevant ones.
- Adds as much of the sorted list as you permit it (with a limit on context) to the LLM context.
This works great on small repos, allowing it to ask you to look at files it thinks are relevant to the task, and adding them to context by asking, but there are a few flaws which make it problematic on big monorepos:
- It assumes all symbols are unique. If you have 10 symbols called
fetchRequest, it assumes those are all the same symbol. - It doesn’t model relevance according to the files you are targeting for changes.
- Roughly, it assumes frequency of usage increases relevance.
On our repo, this resulted, for example, in our entire repo map mostly being our feature flag methods, or really general symbols like name() .
Solution
We figured this could be fixed by improving aider and giving it alternative repo map strategies that you can select for different task types.
The aider code is clean, with well separated concerns, so we found it easy to find the repo map code and refactor it a little so that we could provide different strategies for building the repo map:
ranked_tags = self.ranking_strategy.get_ranked_tags(
chat_fnames,
other_fnames,
mentioned_fnames,
mentioned_idents,
progress=spin.step,
get_rel_fname=self.get_rel_fname,
get_tags=self.get_tags,
)
This outsources the job of listing the ranked tags to a strategy class, and we can then build many of them.
First, we extracted the default PageRankStrategy , and then created our new ImportFloodStrategy.
Now, we could invoke aider like this:
aider --ranking-strategy importflood --haiku --show-repo-map apps/mobile/src/components/PhotoCarousel/PhotoCarousel.tsx
This, combined with the editable mode of pip (pip install -e), with venv, gave us a very easy way to test our changes, aider would print the repo map, and we could easily test against multiple repos to see if the repo map ‘looked’ any more relevant.
ImportFloodStrategy
First, let’s discuss what we really want for our specific use case.
Mostly, the TypeScript errors we were having fell into two categories:
- Easily fixed without any context.
- Type mismatches, need to know the types in order to fix the problem.
2 are the ones we need to improve aider to fix.
Imagine a situation whereby a /user api route imports a User model type, which is also dependent on an Article model type, and the issue is that a field in Article is optional, and isn’t being handled.
This is a very common type of error in our 10,000~ errors.
For those, we want to build a repo map that looks something like this:
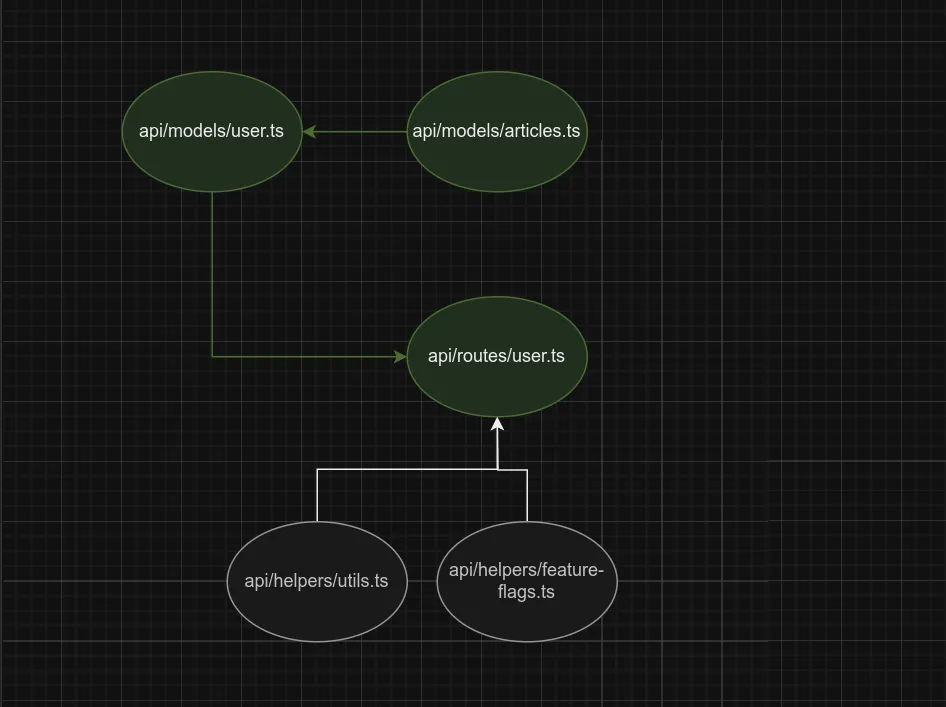
api/routes/user.ts imports all of the files in the diagram. I’ve highlighted in green the ones that we really need to see to fix the problem.
So, let’s write a new strategy that works like this:
- Identify all symbols we use in our target file.
- Follow the imports and find their definitions.
- Add those definitions to our repo map with a high priority.
- For the remainder of the repo map, if we have any space, populate it with the default Pagerank behaviour.
Our get_ranked_tags implementation looks like this:
def get_ranked_tags(
self,
chat_fnames,
other_fnames,
mentioned_fnames,
mentioned_idents,
progress=None,
get_rel_fname=None,
get_tags=None,
):
# Collect all files
chat_rel_fnames = set(get_rel_fname(fname) for fname in chat_fnames)
# Collect files with definitions for imports from chat files
ranked_files = set()
for chat_fname in chat_fnames:
chat_rel_fname = get_rel_fname(chat_fname)
imported_modules = self.parse_imported_modules(chat_fname)
# Using a language specific resolver, resolve the imports.
resolve_from_chat_fname = lambda module_name: Resolver.resolve_any(chat_fname, module_name)
imported_files = [f for f in map(resolve_from_chat_fname, imported_modules) if f is not None]
for fname in imported_files:
rel_fname = get_rel_fname(fname)
if not rel_fname.startswith('..'):
ranked_files.add(rel_fname)
# Remove chat files from ranked files
ranked_files -= chat_rel_fnames
# Create ranked tags list
ranked_tags = []
for file in ranked_files:
tags = get_tags(file, file)
ranked_tags.extend(tags)
return ranked_tags
Now, we encounter a problem.
Before, aider could use tree-sitter to parse any language file, build an AST, and find all the symbols, and tree-sitter has a large set of language parsers available that it can use.
However, the repo map used to be built by just parsing every file in the repository (it was cached, to speed up future invocations), and now we need to actually resolve imports.
This can be tricky, because there are many ways to import things and they’re different across all languages, TypeScript, for example, can import things like:
import * as myUtils from '../lib/utils'
import { awsUtils } from '@aws/utils'
import { monorepoUtils } from '@meetsmore/utils'
// many more
And these files could be in node_modules, they could be relative, they could be in our monorepo workspace, and how they’re resolved even depends on our resolution strategy and package manager!
So, we need to write Resolvers for each language.
class PythonResolver(Resolver):
def resolve(from_fname, module_name):
"""Resolve a module name to its defining file (python only)"""
# Add the directory of the importing file to sys.path
file_dir = str(Path(from_fname).parent.absolute())
sys.path.insert(0, file_dir)
try:
# Try to find the module spec
spec = importlib.util.find_spec(module_name)
if spec and spec.origin and Path(spec.origin).exists():
return spec.origin
except (ImportError, AttributeError):
pass
finally:
# Remove the added path
sys.path.pop(0)
return None
Current Status
We’ve done the following:
- Built a harness for scripting
aiderbased on TypeScript errors. - Modified
aiderso it supports alternate repo mapping strategies. - Built an alternative mapping strategy that follows imports.
- Built Python and JavaScript resolvers.
Next steps:
- Finish the JavaScript resolver.
- Use the modified
aiderto fix our TypeScript errors. - Open a PR in the
aiderrepository to add our work back to the public domain.
We’ve paused this work for now as we have some other more urgent priorities, but we expect to finish it in January 2025.