Hi, this is David(@tianweiliu) from MeetsMore’s Site Reliability Engineering team, again.
Today I will talk about how ECS was hard-limiting us on the number of tenants we can serve our new Custom Report feature to, and how migrating to EKS helped solve that issue and also made it a lot easier for us to onboard new tenants.
Background
- We host dedicated services for each of our tenant to serve the new Custom Report feature (to provide our clients customizable data visualization dashboards and more), in order to ensure data and identity separation. It also gives us more granular control on compute resource.
- Each service is identified with a subdomain name using the tenant key.
- We had the most straight forward ECS setup
- We hosted each tenant as one individual ECS service, all in one big ECS cluster.
- We created one Target Group for each ECS service.
- We created one Application Load Balancer and route traffic based on SNI to different Target Groups.
- We had a Cloudfront distribution with AWS issued wildcard certificate attached, and all of the traffic was forwarding to the single Application Load Balancer.
- We had Route53 zone of the wildcard domain set to direct to the Cloudfront distribution.
- Every time we needed to onboard a new tenant, we had to:
- Create a new ECS service
- Create a new ECS Task Definition
- Create a new Cloudwatch log group
- Create a new Target Group
- Create a new ALB listener rule
The AWS Quota
As we gradually released the new feature to more and more tenants, we were faced with an problem: We were running out our quota.
At first, since we were doing routing with SNI in a single ALB, we thought we were limited by how many rules we could have, which was only 100. It could be increased 200 by contacting AWS support which we did.

When we were releasing to the 101st tenant, we realized that we could not actually go beyond 100 tenants as we could only have 100 Target Groups per ALB, and it was a hard limit.
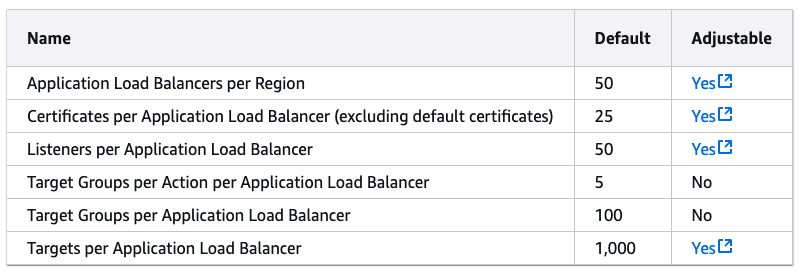
We could also design a multi-ALB architecture or venture on approaches like sharing Target Groups between services using different ports, etc., but managing routing would become significantly harder as we would need to route the traffic based on domain ourselves or with Cloudfront distribution behaviors. We would always be limited by yet another quota or operation overheads. It was time to move on.
The Migration to EKS
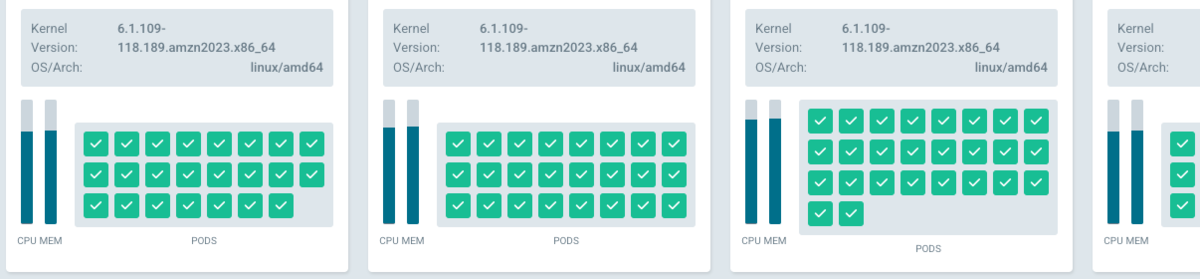
We built a single helm chart that manages a tenant list in helm values, and the template creates a Deployment/Service for each tenant.
The chart only creates one Ingress that points to a single ingress-nginx ingress controller Service exposed as a NLB. Each of the domains were set as one rule in the same Ingress that points to corresponding Services.
Lastly, we set our Cloudfront distribution to forward all traffic to NLB.
The Benefits
As long as we have enough compute resource in our node. There is really no limiting factor on how many tenants we can onboard now.
We no longer need to apply and terraform changes when onboarding new tenants, since there is no AWS resource that needs to be created for each tenant. Everything is handled by the list in helm values. Unless, of course, that we ran out of resources in nodes and need to provision more nodes.
For that, we are in the process of making the nodes fully managed by Karpenter, which will give us on-demand capacity and bin-packing, which eliminates the only remaining manual task other than managing the tenant list.
From:* Couple hours for
- Two codebase to change
- Three PRs to approve
- Terraform to apply
Onboard new tenants with terraform + ECS
To:
Less than 15min for
- One codebase to change
- One PR to approve
- No terraform
Onboard new tenants with EKS
That’s all for today’s sharing. Thank you for reading!
Be sure to check out other articles from Advent Calendar written by my amazing colleagues here at MeetsMore, and if you haven't, check out my previous Advent Calendar entry about Declarative GitOps with Argo CD!
See you next time!