はじめに
こんにちは、ミツモアのエンジニアの井藤です。
この記事では、見積書PDFを構造化JSONに変換するOCR機能の開発を通じて確立した、AIエージェント開発の方法論を紹介します。
開発の過程で「組み合わせ爆発」に陥りかけましたが、AIを使って"使い捨て"の実験基盤を素早く構築し、高速に実験を回すことで、データ駆動でアーキテクチャを決定できるようになりました。
この記事で紹介する5つのポイント:
- 実験基盤はAIで素早く作る — 使い捨てでいいからAIを存分に活用
- 指標はビジネス要件から導出する — 「金額がズレたらアウト」→測定可能な定義へ
- エラーを分類して代表ケースを選ぶ — 全部盛りではなく軸を設計
- LLM as a Judgeで分析を自動化する — どこが壊れているかを特定
- アーキテクチャはデータで決める — 勘ではなく実験結果で判断
LLMを使った構造化・分類タスクや、精度が厳しく求められるAI機能の開発で、同じような課題に直面している方の参考になれば幸いです。
なお、この記事で「AIで作った」と言っているのは、使い捨ての実験基盤(データセット生成スクリプト、評価ロジック等)です。最終的なプロダクションコードは別途作成しています
1 ストーリー
1-1 導入
背景: なぜこの機能が必要か
ミツモアでは、フィールドサービス業向けのBtoB SaaS「プロワン」を開発しています。プロワンは、現場作業を行う企業の見積・受発注・請求などの業務を一元管理するプロダクトです。
プロワンには、協力会社から受け取った見積書を元に自社の顧客むけに見積書を作成する機能があります。しかし、見積書はPDFや画像で届くため、項目名、数量、単価、金額を手作業で入力する必要がありました。見積書によっては数十行から数百行の明細があり、見積書を送ってくる協力会社は何十社にもなることもあります。そのため、入力ミスのリスクと作業時間が課題でした。
そこで、PDFや画像をアップロードするだけで構造化データとして取り込める機能を開発することになりました。
従来のOCR(文字認識)だけでは不十分です。見積書の「構造」—階層関係や項目の親子関係—を理解する必要があります。ルールベースでの構造化は見積書フォーマットの多様性に対応しきれないため、LLMを使って「意味を理解して構造化」するアプローチを採用しました。
実験で見えてきたこと
この記事で紹介するのは、プロダクション実装の前段階—実験によるアーキテクチャ選定の話です。
実験の結果、以下のアーキテクチャであれば要件を満たせる見通しが立ちました。
flowchart LR
A[PDF] --> B[Claude Sonnet]
B -->|文字起こし| C[Markdown]
C --> D[Claude Haiku]
D -->|構造化| E[JSON]
実験データ(16ケース × 各複数回実行)での結果:
- 金額精度: 100%
- 処理時間: 約83秒/PDF
- コスト: 約20円/PDF
この見通しを得るまでに、どのような実験基盤を作り、どのようにアーキテクチャを選定したかを紹介します。
ビジネス要件: 金額が1円でもズレたらアウト
このプロジェクトで最も厳しかったのは、金額精度の要件です。
金額が間違った見積書を出すわけにはいきません。これは当然の話ですが、問題はその厳しさです。仮に「精度95%」でも、100行の見積書なら5行は間違っている計算になります。数円〜数十円の誤差を100行の中から人手で見つけて修正するのは、手入力より大変です。
「だいたい合っている」では業務に使えません。このビジネス要件を満たすアーキテクチャを、データ駆動で発見しました。
最大の課題: 組み合わせ爆発
しかし、ここに至るまでは迷走の連続でした。
試したいことが次々と出てきます。モデルはHaiku、Sonnet、Gemini、GPT-4o、DeepSeek...。アーキテクチャは1段階、2段階、並列...。チャンクサイズは1ページ、3ページ、5ページ...。
組み合わせ爆発です。何を比較しているのかわからなくなりました。
解決策: AIで実験基盤を構築する
この迷走を解決するために確立したアプローチがあります。
- 指標を先に決める(PMとの対話から)
- データセットを体系的に作る(次元で設計)
- 評価基盤をAIと一緒に作る(使い捨てでいい)
- 実験を回してデータで判断する
これによって迷走から抜け出して自信を持ってデータ駆動でアーキテクチャを選定できるようになりました。
1-2 見積書OCRの難しさ
見積書はフラットなテキストではありません。「木構造」です。
見積書 ├─ 1. 内装工事 (金額: 子の合計) │ ├─ 1.1 床工事 ¥450,000 │ └─ 1.2 壁工事 ¥380,000 ├─ 2. 電気工事 (金額: 子の合計) │ └─ ... └─ 合計: ¥1,180,000
この構造を正しく認識しないと、金額の合計が狂います。
難しさ1: 階層構造の認識
親子関係を間違えると金額の合計が狂います。しかも、階層の表現方法は見積書ごとに異なります。インデントで表すもの、番号(1., 1.1, 1.1.1)で表すもの、サマリーと内訳が分離しているもの、これらが混在しているもの...。
難しさ2: 品質バリエーション
実務で届く見積書は、クリーンなPDFばかりではありません。FAXで送られてきたもの、スマホで撮影されたもの、何度もスキャンされて劣化したもの。クリーンなPDFだけでテストしても、実務では使えません。
難しさ3: ビジネス要件の厳しさ
繰り返しになりますが、金額は1円でもズレたらアウトです。精度90%では不十分。100%を目指す必要があります。
1-3 迷走と転機
とりあえず作ってみた
最初は「とりあえず作ってみよう」で始めました。
結果は厳しいものでした。階層構造がないPDFは処理できましたが、階層構造があるPDFはうまくいきません。コストも高すぎました(30ページで200円くらい)。時間もかかりすぎます。
問題を解決しようとして発散
問題を解決しようとするたびに、新しいアイデアが浮かびます。
大きなPDFが処理できない → 分割処理で解決しよう。分割したら階層が崩壊した → 2段階パイプラインで解決しよう。2段階にしたらコストが高騰した → 並列化?チャンクサイズ最適化?OCR専用モデル?
気づいたら、試したいことを書き出したら膨大な数になっていました。組み合わせの爆発です。
転機: 「何を指標にしていいかもわからず」
ここで転機が訪れました。
大学時代のゼミを思い出して実験記録をつけようと思いましたが、何を指標にしていいかわかりません。テストデータもそんなに持っていません。
この時、気づきました。モデルやアーキテクチャを試す前に、評価基盤を先に作るべきだと。
「PDFを自分で作ればいい」という発想
評価基盤を作るには、まずテストデータが必要です。でも、実際の見積書PDFを使おうとすると、「正解データ」を人手で作成しなければなりません。数十、数百行の見積書の正解JSONを手作業で作る...これでは時間がかかりすぎます。
そこで思いついたのが、「PDFをプログラムで生成する」というアプローチでした。
プログラムでPDFを生成すれば、生成時点で正解データも一緒に出力できます。PDFと正解JSONがセットで手に入る。これなら評価を自動化できます。
ただ、PDFを生成するスクリプトを自分で書くのは大変です。PDFライブラリの調査、画像処理の実装、見積書の階層構造のモデリング...。
ここでAIの出番でした。
AIに実験基盤を作ってもらう
AI(claude code)に「見積書PDFを生成するスクリプトを作って」と依頼してみました。
見積書PDFを生成するスクリプトを作って。 要件: - 4種類の階層表現(インデント/番号/サマリー分離/混在) - 4種類の品質(clean/FAX風/スマホ撮影/再スキャン) - Ground Truth(正解JSON)も同時に生成 - レンダリングと劣化処理までやって
1時間もしないうちに、動くスクリプトが出てきました。PDFライブラリや画像処理の知見がなくても、設計さえ伝えればAIが実装してくれます。(もちろんこのプロンプト一発で動くスクリプトが出てきたわけではなく、これに続けてAI(claude code)と会話して詳細は詰めています。がそれも含めて1時間程度でした。)
評価ロジックも同様です。「金額が100%一致した割合を計算するevaluatorを書いて」と依頼すれば、AIがコードを書いてくれます。
こうして、実験のサイクルが回り始めました。問題を発見したらAIと相談し、必要なスクリプトを作ってもらい、実験を回し、結果を分析する。方法論は人間が決め、実装はAIに任せる。このスタイルが確立していきました。
実験結果の管理: Langfuseとの出会い
実験を回し始めると、次の問題が出てきました。結果がどこにあるかわからなくなるのです。
「さっきの実験、Haikuの精度いくつだったっけ?」「さっき試したあの設定、再現できる?」
ログファイルをgrepして探す日々。これではスケールしません。
そんな時、上司からLangfuseを紹介されました。LLMアプリケーションの可観測性ツールです。
使ってみると、まさに求めていたものでした。テストケースをデータセットとして登録しておけば、実験ごとに結果が記録される。ダッシュボードで実験間の比較ができる。失敗したケースのトレースを追って、どこで何が起きたかを確認できる。
これで実験結果をチームで共有できるようになりました。PMや上司との議論も、「このケースで失敗しています」と具体的なデータを見せながらできるようになりました。
設計に集中できるようになった
振り返ると、AIを活用することで「設計」に集中できるようになったのが大きかったです。
どんなテストケースが必要か、どんな指標で評価すべきか—これは業務ドメインを理解している人間が考えるべきことです。一方で、PDFを生成するスクリプトや評価ロジックの実装は、AIに任せられます。
PMとの対話で「実際には10度傾いた見積書なんて来ないよ」という情報を得る。その情報をもとに、現実的なテストケースを設計する。そして、その設計をAIに伝えて実装してもらう。
この役割分担ができたことで、迷走から抜け出すことができました。
1-4 まとめ
ここまでのストーリーを振り返ると、迷走から抜け出せた理由は3つありました。
- 評価基盤を先に作る — 何を試すかより、何で判断するかを先に決める
- データセットをプログラムで生成する — 正解データ作成のボトルネックを解消
- AIに実装を任せ、設計に集中する — 使い捨てコードは自分で書かない
このアプローチは、見積書OCRに限らず、LLMを使った構造化タスクや精度が求められるAI機能開発で応用できるはずです。
ここから先の読み方
2.設計の詳細以降では、具体的な設計判断とその理由を紹介します。
- 自分のプロジェクトでも試したい方: 定量評価の設計(2-1)とデータセット設計(2-2)が参考になります
- 結論だけ知りたい方: 3 結果と結論のセクションに最終的なアーキテクチャと数値があります
では、具体的な設計の話に入ります。
2 設計の詳細
2-1 定量評価を可能にする設計
AIエージェント開発の難しさ: 定性的な入出力
AIエージェント開発で最も難しいのは、入力も出力も定性的になりがちなことです。
見積書OCRの場合、入力はPDF、出力は構造化されたJSON。「うまくいった」「なんか違う」という判断は目で見ればできますが、それでは実験が回りません。
❌ 定性的な評価: 「このJSON、なんか階層が違う気がする...」 「金額は合ってるけど、項目名が微妙に違う」 → 10件見るのが限界。100件は無理。
モデルを比較したい、アーキテクチャを比較したい、設定を変えて試したい。でも、毎回目で見て判断していたら、せいぜい10件が限界です。数百件の実験を回すには、定量的な評価が必須でした。
業務目標を定量指標に変換する
まず、「うまくいった」を定量的に定義する必要があります。
PMとの対話から、業務目標を引き出しました。
「金額が間違っていたら使い物にならないよね。1円でもズレていたら、結局人が確認しないといけない」
これを定量指標に変換します。
業務目標: 「金額が1円でもズレたらアウト」
↓
定量指標: is_amount_perfect = 金額が100%一致しているか
目標値: 全ケースで100%一致
※LLMは確率的な挙動をするため、各テストケースを複数回実行し、評価しました。
「精度」という曖昧な言葉では実験できません。「金額が100%一致しているか」という測定可能な定義に変換することで、初めて比較が可能になります。
同様に、他の業務目標も定量指標に変換しました。
| 業務目標 | 定量指標 | 目標値 |
|---|---|---|
| 金額が1円でもズレたらアウト | is_amount_perfect | 全ケースで100%一致 |
| コストは30円以下で | cost_per_pdf | ≤30円 |
| 待ち時間は5分以内で | duration_per_pdf | ≤300秒 |
自動評価を可能にする: Ground Truthの設計
定量指標を定義しても、それを自動で計算できなければ意味がありません。
「金額が100%一致しているか」を判定するには、正解データ(Ground Truth)が必要です。
ここで重要な設計判断がありました。PDFをプログラムで生成することで、Ground Truthを生成時に確定させるというアプローチです。
プログラムでPDFを生成:
{
items: [
{ name: "床工事", amount: 450000 },
{ name: "壁工事", amount: 380000 }
],
total: 830000
}
↓
このデータからPDFをレンダリング
↓
PDFとGround Truthが同時に手に入る
実際の見積書PDFを使う場合、Ground Truthを人手で作成する必要があります。数十行の見積書の正解JSONを手作業で作る...これでは時間がかかりすぎます。
プログラムで生成すれば、PDFと正解データがセットで手に入り、評価を完全に自動化できます。
関数で比較する
Ground Truthが確定していれば、評価は関数で書けます。
function evaluate(output: EstimateJSON, groundTruth: EstimateJSON): EvalResult { // 金額の完全一致をチェック const amountMatch = output.items.every((item, i) => item.amount === groundTruth.items[i]?.amount ) // 成功の定義: 金額が100%一致 const isSuccess = amountMatch && output.items.length === groundTruth.items.length return { is_amount_perfect: amountMatch, pdf_success: isSuccess, // ... } }
is_amount_perfectは各PDFに対する真偽値です。Langfuseで集計することで「金額が100%一致したケース数」を確認できます。
これで、人間が目で見なくても「成功/失敗」を判定できます。
大量実験が可能になる
定量指標 + プログラム生成 + 関数評価。この3つが揃うことで、大量の実験を回せるようになりました。
定性的な評価(目視): - 1件あたり5分 × 10件 = 50分 - それ以上は集中力が持たない 定量的な評価(自動): - 16パターン × 3回実行 = 48件 - 全自動で実行、結果はLangfuseに記録 - 1時間で複数の設定を比較可能
モデルを変えて実験、アーキテクチャを変えて実験、設定を変えて実験。すべて自動で評価され、数値で比較できます。
「Sonnetは100%、Haikuは62.5%」—このデータがあるから、Sonnetを採用するという判断ができました。定性的な「なんとなくSonnetの方が良さそう」では、自信を持った判断はできません。
AIがあれば数時間で作れる
ここまでの仕組み—定量指標の定義、PDF生成スクリプト、評価関数—を自分で一から実装しようとすると、ライブラリの調査も含めて数日はかかったでしょう。
しかし、上でも述べたようにコーディングエージェントに「こういう仕組みを作りたい」と伝えれば、数時間で動くものが出てきます。
実験基盤は「動けばいい」使い捨てのコード。完璧である必要はなく、正しい判断をするためのデータが得られればいい。この割り切りとAIの組み合わせで、初心者でも短時間で実験を回せる状態に持っていけます。
ポイント
AIエージェント開発を定量的な実験に変換するために必要なこと:
- 業務目標を定量指標に変換する: 「金額がズレたらアウト」→
is_amount_perfect - Ground Truthを自動生成する: プログラムでデータを生成し、正解を確定させる
- 評価を関数で書く: 人間の目視判断を排除し、完全自動化する
これにより、数百件の実験を回し、データで意思決定できるようになります。
2-2 データセット設計-エラーケースの分類と代表ケースの選定
最初の失敗: 難しいケース全部盛り
次に必要なのはテストデータです。
最初は、失敗したケースの特徴を全部盛り込んだデータを作りました。数百行あって、ページ数も多くて、階層構造もある。「これで精度が出れば、どんな見積書でもいける」と思っていました。
結果は惨敗。精度が出ないのですが、なぜ失敗しているのかわかりません。ページ数の問題?階層構造の問題?両方?全部盛りにしてしまったせいで、原因の切り分けができなくなっていました。
エラーケースを分類する
「全部盛り」の失敗から学んだのは、エラーケースを整理して分類する必要があるということでした。
OCRが失敗する要因を整理すると、大きく2つの軸に分類できます。
エラーの分類:
├─ 品質系(文字認識が難しくなる)
│ 例: 解像度低下、ノイズ、ブラー、傾き、汚れ...
│
└─ 構造系(構造認識が難しくなる)
例: 階層の深さ、ページ数、表現方式の違い...
品質系のエラー: 解像度を下げる、ノイズを入れる、ブラーをかける—これらは表面的には違いますが、共通点があります。「文字認識が難しくなる」という点です。
構造系のエラー: 階層を深くする、ページを増やす、複数方式を混在させる—これらの共通点は「構造認識の複雑さ」です。
代表ケースを選定する
分類ができたら、次は各分類から代表的なケースを選びます。
すべてのバリエーションをテストする必要はありません。同じ分類に属するエラーは、代表的なケースでカバーできます。
品質系の代表ケース:
「ノイズ」「ブラー」「低解像度」を個別にテストする必要はなく、実務で発生する典型的な劣化パターンを選べば十分です。
- FAX品質(75dpi + ノイズ)
- スマホ撮影(パースペクティブ歪み)
- 再スキャン(ブラー)
構造系の代表ケース:
実験を重ねる中で気づいたのは、階層の「深さ」より「表現方式」の方が影響が大きいということでした。5段の階層でも、番号(1.1.1.1.1)で表現されていれば認識できる。しかし、サマリーと内訳が別ページに分離していると、2段でも失敗する。
つまり、構造系は「表現方式」を軸に代表ケースを選ぶべきです。
業務要件による絞り込み
代表ケースを選ぶ際、もう一つ重要な観点があります。業務で実際に発生するかどうかです。
PMに実務の相場感を聞きました。
「60ページの見積書が来ることもあるけど、それは特殊なケース。普通は6ページくらいが上限だよ」
「10度傾いた見積書?そんなの来たことないよ」
「解像度が極端に低いものは、そもそも人間も読めないから再送してもらう」
この対話で、テストすべきケースが絞り込まれました。
| ケース | 業務での発生頻度 | 判断 |
|---|---|---|
| 10度以上の傾き | ほぼない | 除外 |
| 極端な低解像度(50dpi以下) | 人間も読めない | 除外 |
| 100ページ超 | 年に数回 | 除外(6ページでテスト) |
| FAX品質(75dpi程度) | 頻繁 | 採用 |
| スマホ撮影 | 頻繁 | 採用 |
| 再スキャン(ブラー) | 頻繁 | 採用 |
| サマリー+内訳分離 | 一定数ある | 採用 |
技術的に対応が難しいケースでも、業務で発生しないなら優先度は下がります。逆に、技術的には簡単でも業務で頻繁に発生するなら必須です。
最終的なデータセット設計
エラーケースの分類、代表ケースの選定、業務要件による絞り込みを経て、最終的に2つの独立した軸でデータセットを設計しました。
軸1: 階層表現方式(構造系の代表ケース)
| パターン | 説明 | 選定理由 |
|---|---|---|
| BASE-1 | インデントで階層表現 | 最も一般的 |
| BASE-2 | 番号(1., 1.1, 1.1.1) | 一般的かつ認識しやすい |
| BASE-3 | サマリーと内訳が別ページ | 最も失敗率が高い |
| BASE-4 | 複数方式が混在 | 実務で一定数存在 |
軸2: 品質バリエーション(品質系の代表ケース)
| パターン | 説明 | 選定理由 |
|---|---|---|
| clean | オリジナル(300dpi) | ベースライン |
| fax-quality | 75dpi + ノイズ | 業務で頻繁に発生 |
| phone-photo | スマホ撮影相当 | 業務で頻繁に発生 |
| re-scanned | 再スキャン(ブラー) | 業務で頻繁に発生 |
最終: 4 階層表現 × 4 品質 = 16パターン
なぜ16パターンで十分か
一見少なく見えますが、このデータセット設計には根拠があります。
1. エラーケースの代表性
エラーを分類し、各分類から代表ケースを選んでいます。「ノイズ」「ブラー」「低解像度」を個別にテストする必要はなく、「fax-quality」が品質劣化を代表できます。
2. 直交する軸での設計
階層表現と品質は独立した問題です。BASE-3で失敗しているなら、それは「サマリー分離」という構造の問題であり、品質とは無関係とわかります。原因の切り分けが可能になります。
3. 業務要件による絞り込み
技術的に難しくても業務で発生しないケース(10度傾き、100ページ超)は除外しています。限られたリソースを、実際に発生するケースに集中できます。
4. 複数回実行による安定性確認
LLMは確率的な挙動をするため、各パターンを複数回実行しています。実際の実験量は、16パターン × 3回実行 × 複数設定で、数百回になりました。
「てんこ盛り」で100パターン作るより、分類に基づいて選定した16パターンを繰り返し実験する方が、問題の特定と改善に有効でした。
2-3 LLM as a Judge-「どこが壊れているか」を特定する
2段階パイプラインのデバッグ問題
ここまでで、指標とデータセットが揃いました。実験を回し始めると、次の問題に直面しました。
実験中のアーキテクチャは2段階パイプラインです。
flowchart LR
A[PDF] --> B[Stage1: OCR]
B --> C[Markdown]
C --> D[Stage2: 構造化]
D --> E[JSON]
精度が出ない時、ログを見ても「結果が違う」としかわかりません。Stage1(文字起こし)の問題なのか、Stage2(構造化)の問題なのか。
手動でMarkdownを確認すれば判別できます。でも16ケース × 複数実験では現実的ではありません。
【補足】LLM as a Judgeとは
LLM as a Judgeは、LLMの出力を別のLLMで評価する手法です。
従来、AIの出力評価には2つの選択肢がありました。
| 評価方法 | 長所 | 短所 |
|---|---|---|
| 人間評価 | 文脈を理解できる | スケールしない |
| ルールベース(完全一致等) | 高速・大量処理可能 | 「意味は同じだが表現が違う」を誤判定 |
LLM as a Judgeは、「人間のように文脈を理解しつつ、大量に評価できる」という中間解です。
今回なぜ適切だったか
今回の評価対象は「構造化が正しいか」という判断です。例えば:
- 「内装工事」と「内装 工事」は同じか?
- カテゴリ行の金額が0になっているのは正しいか?
- 階層構造は意図通りか?
これらは文脈理解が必要で、単純な文字列一致では判定できません。かといって、数十回から数百回の実験結果を人間が確認するのは非現実的です。
LLM Judgeでの注意点
AIに相談したところ、LLM as a Judgeを提案されました。
マルチステージパイプラインを個別にテストするのは当たり前です。Stage1はStage1、Stage2はStage2で評価する。
ただ、LLM as a Judgeでは一つ注意点があります。LLMは明示しないと「親切心」で余計な評価をしてしまうのです。
例えばStage2(Markdown→JSON)の評価で、「Markdownの内容が正しいか」まで評価されると困ります。それはStage1の責任であって、Stage2の評価に混ぜるべきではありません。
【補足】Stage別評価の実装
Stage1とStage2を別々のLLM呼び出しで評価し、最後に「根本原因」を判定します。
const [stage1Result, stage2Result] = await Promise.all([ judgeStage1(groundTruth, generatedMarkdown, diffSummary), judgeStage2(generatedMarkdown, jsonResult), // groundTruthは渡さない ]) const rootCause = determineRootCause(stage1Result, stage2Result) // → 'stage1_ocr' | 'stage2_structuring' | 'both' | 'none'
ポイントは、judgeStage2にはgroundTruthを渡さないことです。渡すと「正解と違う」という評価が混入してしまいます。
Stage2評価のプロンプト(抜粋)
LLMに「余計な評価をするな」と伝えるため、「評価すべきでないこと」を明示しました。
**重要な前提**: - あなたの役割は「構造化処理の品質評価」です - 入力Markdownの内容が正しいかどうかは評価対象外です - 「与えられた入力Markdown」を「どれだけ正確にJSONに構造化できたか」のみを評価してください ## ❌ 評価すべきでないこと(重要) これらはStage1(PDF→Markdown)の責任範囲です: - Markdownの内容そのものが正しいか(OCR精度) - Markdownに含まれる金額・数量が正しいか **評価原則**: Markdownが不完全でも、その内容を忠実にJSON化できていれば成功です。
「何を評価するか」だけでなく「何を評価しないか」を書く。LLM as a Judgeを使う際の実践的なTipsです。
Langfuseとの統合
LLM Judgeの結果はLangfuseに記録し、実験結果と一緒に確認できるようにしました。
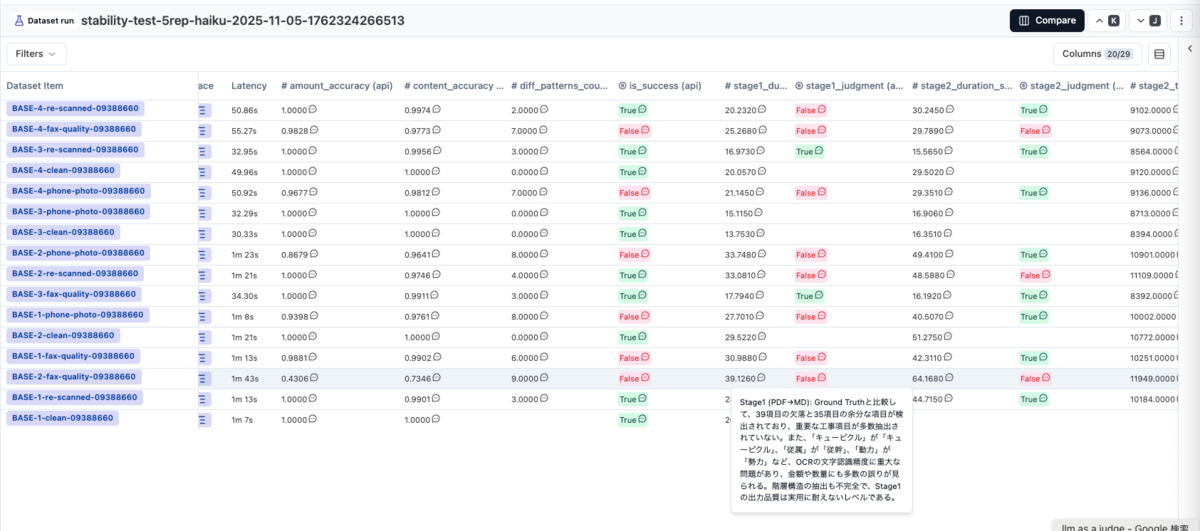
stage1_judgment、stage2_judgmentの列で、どのStageが原因かが一目でわかる
失敗ケースにカーソルを合わせると、詳細な理由が表示されます。
Stage1 (PDF→MD): Ground Truthと比較して、39項目の欠落と35項目の余分な項目が検出されており、重要な工事項目が多数抽出されていない。また、「キュービクル」が「キュービクル」、「従属」が「従幹」、「動力」が「勢力」など、OCRの文字認識精度に重大な問題があり...
数百回の実験結果から、「どれを確認すべきか」がすぐにわかります。全件を手動で確認する必要がなくなりました。
OCRがボトルネックだった
LLM Judgeを導入して実験を回したことで何が原因か明白になりました。
失敗ケースの大半がStage1(OCR)起因だったのです。
[LLM Judge] Root Cause: stage1_ocr Stage1 (PDF→MD): いくつかの階層が抜け落ちている Stage2 (MD→JSON): Markdownの内容は忠実にJSONに変換されている。問題なし
Stage2は問題なく動いていました。つまり、Stage2の改善に時間を使う必要がなかったのです。
ボトルネックが特定できたことで、「Stage1のOCR精度を上げる」という明確な方針が立ちました。
2-4 まとめ
2.設計の詳細では、実験ループを回すために必要だった3つの設計を紹介しました。
- 定量評価の設計: 業務要件から「金額100%一致」を測定可能な指標に変換
- データセット設計: エラー分類に基づく代表ケースの選定で16パターン
- LLM as a Judge: 失敗原因の自動特定でデバッグを効率化
これらの設計があって初めて、「どのアーキテクチャを採用すべきか」をデータで判断できるようになりました。
次に、実際の実験結果と最終的なアーキテクチャ決定を紹介します。
3 結果と結論
3-1 評価基盤を使った意思決定
迷走から整理へ
上で紹介した評価基盤(定量指標・データセット・LLM Judge)が整ったことで、状況が変わりました。
迷走フェーズでは「とりあえず試す → なんか違う → 別のを試す」の繰り返しでした。基盤ができてからは「この比較をすれば、この意思決定ができる」が明確になりました。
以下、アーキテクチャ決定に至った3つの実験を紹介します。
実験1: アーキテクチャ選定(1段階 vs 2段階)
最初の意思決定は、アーキテクチャの選択です。
- 1段階: PDFを直接LLMに入れてJSONを出力
- 2段階: PDF→Markdown→JSON(中間表現を経由)
Haikuで両方を試しました。
【補足】1段階 vs 2段階の実験結果
| BASE | 2段階 | 1段階 |
|---|---|---|
| BASE-1(インデント) | 50% | 67% |
| BASE-2(番号) | 50% | 33% |
| BASE-3(サマリー分離) | 50% | 0% |
| BASE-4(混在) | 0% | 17% |
注目すべきはBASE-3です。サマリーと内訳が別ページに分かれている形式で、1段階では成功率0%でした。
実務でBASE-3形式は存在します。1段階では実務に使えないケースがある。
決定: 2段階を採用。
実験2: ボトルネックの特定(LLM Judge活用)
上でで紹介したLLM Judgeを使い、失敗ケースの原因を分析しました。結果、大半がStage1(OCR)起因と判明。Stage2は正常に動作していました。
発見: ボトルネックはStage1(OCR)。
実験3: OCR改善の試み
Stage1のOCR精度を上げる方法を探りました。
試み1: OCR専用モデル
OCRに特化したモデルなら、汎用モデルより精度が高いのではないか。コストも下がるかもしれない。
結果は意外なものでした。
OCR専用モデルの結果
金額の抽出自体は成功していました。しかし、Stage1(PDF→Markdown)の評価が悪い。
原因を調べると、日本語対応の問題でした。
- 日本語が中国語の漢字で出力される
- 一部の文字が正しく認識されない
試したモデルは多言語対応を謳っていましたが、日本語の精度は実用レベルではありませんでした。
この実験から得られた知見があります。
- 現時点のOCR専用モデルは日本語対応が不十分
- 日本語に特化したOCR専用モデルなら有効かもしれない(その実験の前に試み2で要件を達成したため、実験せず)
試み2: 高性能な汎用モデル(Sonnet)
OCR専用がダメなら、汎用モデルの性能を上げる方向で試しました。
Stage1のモデルをHaikuからSonnetに変更して比較しました。
Haiku vs Sonnetの実験結果(Stage1)
| 指標 | Sonnet | Haiku |
|---|---|---|
| 金額一致率 | 16/16ケース | 10/16ケース |
| コスト/PDF | 約20円 | 約11円 |
| 処理時間 | 83秒 | 60秒 |
Sonnetはコストが2倍ですが、金額一致率は100%。ビジネス要件を満たせるのはSonnetだけでした。
決定: Stage1にSonnetを採用。
「要件を満たしたら止める」という判断
ここで実験を止めた理由を補足します。
最適なアーキテクチャを見つけることが目的ではありませんでした。要件を満たすアーキテクチャを見つけることが目的でした。
| 指標 | 結果 | 目標値 | 達成 |
|---|---|---|---|
| 金額精度 | 16/16ケース | 全ケースで100%一致 | ✅ |
| 処理時間 | 83秒 | 5分以内 | ✅ |
| コスト | 約20円/PDF | 30円以下 | ✅ |
すべての目標を達成しました。もっと安いモデル、もっと速い構成があるかもしれません。でも、それを探す時間があるなら、プロダクション実装を進めた方がいい。
なお、ここでの16ケースは「業務ドメインとエラー分類に基づく代表ケース」です。本番投入後は実際の見積書データを使った評価を継続的に回していく前提で、この段階では「代表ケースで要件を満たすこと」を確認しました。
Langfuseにはプロンプト管理機能があります。プロダクションに投入した後でも、プロンプトやモデルの変更は可能です。最適化は後からでもできる。今は「動くもの」を作ることを優先しました。
3-2 まとめ-5つの原則
この開発を通じて確立した5つの原則をまとめます。
原則1: 実験基盤をAIで効率的に構築する
従来のアプローチでは、「完璧な評価基盤を作る → 実験を始める」という順序になりがちです。でも、基盤構築に時間がかかると、実験が始まりません。
今回は、「AIと相談しながら使い捨て基盤を作る → すぐ実験 → 結果を見て改善」というサイクルを回しました。
実験基盤は「動けばいい」。目的は正しい判断をするためのデータを得ることです。
原則2: 指標をビジネス要件から導出する
「精度」という曖昧な言葉を、測定可能な定義に変換する。
PMとの対話から「金額が1円でもズレたらアウト」という要件を引き出し、それを「is_amount_perfect(金額100%一致)」という指標に変換しました。
原則3: エラーを分類して代表ケースを選ぶ
難しいケースを全部盛りにすると、失敗した時に原因がわかりません。
エラーを分類し、各分類から代表ケースを選定する。さらに業務要件で絞り込む。これにより、少ないパターンで原因の切り分けが可能になります。
原則4: LLM as a Judgeで分析を自動化する
大量の実験結果を人間が目視で確認するのは現実的ではありません。
LLM as a Judgeを活用すれば、失敗ケースの原因分析を自動化できます。今回は「Stage1とStage2のどちらが原因か」を自動判定することで、ボトルネックを特定できました。
原則5: アーキテクチャはデータで決める
「visionモデルに文字起こしから構造化まで全部やらせた方が、階層構造をうまく把握できそう」—そう思っていました。
データは違う結論を示しました。1段階ではBASE-3(サマリー分離形式)が全滅。2段階の方が安定していたのです。
勘ではなく、データで判断する。直感が外れることもあるからこそ、実験が必要です。
おわりに
AIエージェント開発は、試行錯誤の連続です。
組み合わせ爆発に陥りそうになったら、一歩引いて実験基盤から作ることをお勧めします。
最初にやるべきは、業務から指標とゴールを決めること。ビジネス要件を測定可能な指標に変換できたから、実験が収束しました。
試してみたい方へ
この方法論を自分のプロジェクトで試す場合、最初のステップは以下の3つです。
- 指標を決める: ビジネス要件から「絶対に外せない条件」を特定する
- データセットを設計する: 最初は5-10ケースのデータセットで十分
- AIに頼む: 「こういうデータセットを生成するスクリプトを作って」と依頼すれば、数時間で動くものができる
チームの関連記事
同じAgentic AI Labの増田が、Langfuseを使った評価パイプラインの具体的な実装方法を紹介しています。本記事では「実験基盤の考え方」を中心に紹介しましたが、実際にコードで評価パイプラインを構築したい方はこちらもぜひご覧ください。
👉 MastraとLangfuseで作るAgentOps:AIエージェントの管理と精度評価
ミツモアでは、フィールドサービス業向けSaaS「プロワン」をはじめとするプロダクト開発に加えて、私の所属するAgentic AI LabというチームではLLMの使用を前提とした機能開発を進めています。実運用データとLLM・Langfuseなどの基盤を組み合わせて、データ駆動でアーキテクチャやプロダクトを設計していくプロセスに興味がある方、AIエージェント開発に本気で取り組みたい方は、ぜひ採用情報をご覧ください。