ミツモアでエンジニアをしている増田(@xmasudahiroto)です。 ミツモアでは、プロダクトへのAIエージェント組み込みに向けて日々試行錯誤を重ねています。 今回は、AIエージェント活用における課題である「エージェントの管理」と「精度評価」について、社内で取り組み初めている内容の一部をご紹介します。
はじめに
生成 AI アプリケーションが高度化するにつれ、AgentOps(エージェントの構築・運用・評価の一連のサイクル) は急速に複雑になっています。特に、複雑化していくエージェントやワークフローの管理と、精度検証の仕組みづくりは、生成AIアプリケーションを運用するうえで大きな課題です。
本記事では、エージェントとワークフローの管理に Mastra、精度評価に Langfuse を用いて、エージェントの管理とオフラインでのデータセットを使った評価を行うOpsについてサンプルを提示します。
Mastra とは?
Mastra は、TypeScript で AI エージェントやワークフローを構築・管理するためのフレームワークです。以下のような特徴があります:
- エージェント定義: LLM モデルとツールを統合したエージェントを簡単に定義できる
- ワークフロー: 複数のステップを組み合わせた処理パイプラインを構築できる
- Mastra Studio: ローカルで起動できる開発用UIで、エージェントやワークフローをGUIで実行・デバッグできる
- REST API: 定義したエージェントやワークフローをAPIとしてすぐに利用できる
Langfuse とは?
Langfuse は、LLM アプリケーションの可観測性(Observability)と評価を行うためのプラットフォームです:
- トレーシング: LLM への呼び出しやツール実行を追跡・可視化できる
- データセット管理: テスト用の入力と期待出力のペアを管理できる
- 評価(Evaluation): データセットに対する推論結果を記録し、スコアリングできる
- プロンプト管理: プロンプトのバージョン管理ができる
エージェント開発のボトルネック:なぜAgentOpsが必要なのか
生成AIアプリケーション、特に自律的にツールを使用する「エージェント」の開発は、従来のソフトウェア開発や機械学習モデルの開発とは異なる特有の難しさがあります。
① 「確率的」な挙動と評価の難しさ
従来のソフトウェアは入力に対して出力が一意に定まりますが、LLMは確率的に挙動します。 開発時によくあるのが、「あるプロンプトで試したら上手くいったのでヨシとする」 パターンです。しかし、それが異なるプロンプトやコンテキストでも、十分な精度で機能するかは保証されません。 「たまたま上手くいった」状態を排除し、信頼できる精度を担保するには、十分な数のデータセットを用いた反復的な検証が不可欠です。
② 評価指標(メトリクス)の複雑さとツールの必要性
従来の機械学習(分類や回帰)では、RMSEやAUCなど評価指標が明確でしたが、エージェントの評価はより多面的で複雑です。
- 出力品質: LLM-as-a-judgeを用いた評価や、期待出力との類似度
- 実行能力: コード生成タスクにおける実行結果の成否
- プロセス: 中間ステップで適切なツールを、適切な引数で呼び出したか
これらは単純な文字列一致だけでは評価できません。多様な評価ロジックを実装し、管理するための専用ライブラリやサービス(本記事で扱うLangfuseなど)が必要になります。
③ PoC(実験)と本番実装の乖離
よくあるパターンとして、Jupyter Notebookや単体のスクリプトで実験(PoC)を行い、本番用にはまた別のコード(APIサーバーなど)を書き直すケースがあります。 これにより以下の問題が発生します。
- 実験で確認した精度が本番で再現しない
- 評価用のコードがメンテナンスされず、形骸化する
- 実験環境と本番環境で、ツールやRAG(検索)の条件が微妙に異なり、バグの原因になる
- 再実装で工数がかかり、スピード感を持った改善ができなくなる
④ 再現性のある評価パイプラインの欠如
継続的な改善には、実験で使用したコードや評価環境が高い再現性を持っている必要があります。
たとえば、「LLMのモデルを最新バージョンに上げる」あるいは「コスト削減のためにオープンソースモデルに切り替える」といった意思決定を行う際、精度がどう変化するかを正確に測定しなければなりません。
- オフライン評価: 2つの異なるエージェント(新旧モデルなど)を、全く同じデータセット・同じ条件下で実行し比較する
- オンライン評価(A/Bテスト): ユーザーからのサムズアップ/ダウン評価を比較する際、特定のパラメータ以外は完全に同じ条件のエージェントを用意する
- 回帰テスト: 過去に使用していたエージェントもいつでも再評価できるように保つ
これらを実現するには、手動の検証ではなく、「条件を厳密に揃えて実行できるパイプライン」 が不可欠です。
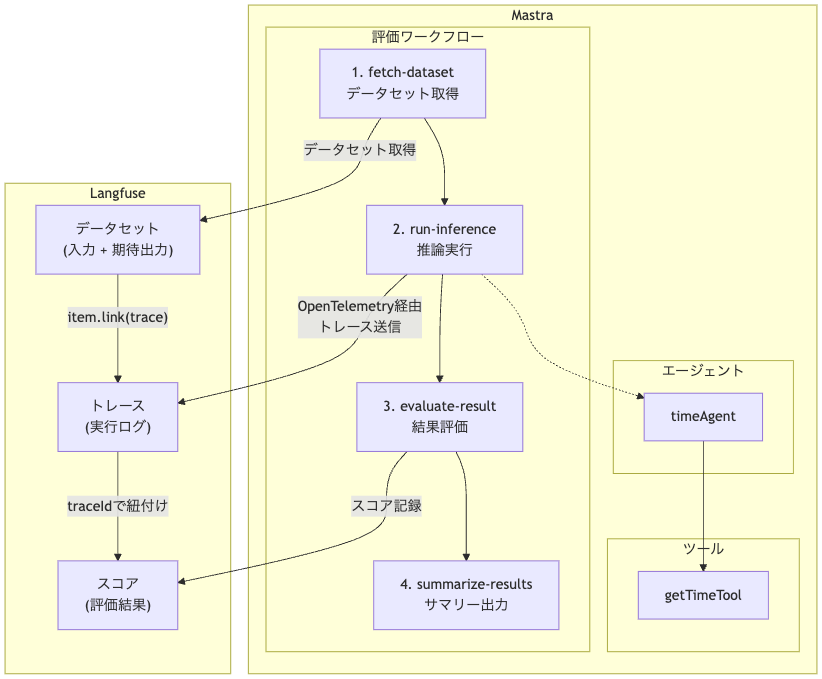
概要
本記事で構築するシステムの流れは以下の通りです:
- Mastraでツール統合したエージェントを作成する
- Langfuseのプロジェクトで正解データセットを作成する
- Mastraのワークフローを使い評価パイプラインを構成する
評価パイプラインの処理の流れは以下の通りになります。
- Langfuseから正解データ取得する
- エージェントを実行し出力を得る
- 出力の結果と正解データを突合し精度を評価する
- 評価した精度をLangfuseに返す
なぜ Mastra と Langfuse を組み合わせるのか?
Langfuse はプロンプトの管理やトレース、データセットの管理に強みを持っており、対して Mastra はエージェントの定義と実行に強みを持ちます。どちらも非常に機能が多く、使い方によっては一つのサービスですべて完結することも多いですが、プロジェクトの状況によっては強みを持つ部分でサービスが分散してしまうこともあります。(例えば、機械学習におけるMLOps の場合は、Feature Store、Pipeline、Logging と Tracing、Deploy で、それぞれのサービスの強みや、既存のシステムとの統合の観点から、それぞれ別のサービスに分散してしまうこともあります)
その前提で、本記事では正解データセットの管理と評価のシステムは Langfuse を使用し、エージェントの管理とデプロイを Mastra で行う構成で実装していきます。
Mastra のセットアップと Studio 起動
プロジェクトの作成
Mastra のプロジェクトは create mastra コマンドで生成できます。本記事では Bun ランタイムを使用します。事前に Bun をインストールしておく必要があります。
bun create mastra
対話形式でセットアップできるので、以下のように入力していきます:
◇ What do you want to name your project? │ mastra-langfuse-demo │ ◇ Where should we create the Mastra files? (default: src/) │ src/ │ ◇ Select a default provider: │ OpenAI │ ◇ Enter your OpenAI API key? │ Enter API key │ ◇ Enter your API key: │ sk-...<APIキー>... │ ◇ Make your IDE into a Mastra expert? (Installs Mastra's MCP server) │ Skip for now
mastra-langfuse-demo にプロジェクトが作成されるので、ここで後続の作業をしていきます:
cd mastra-langfuse-demo
1.2 Mastra Studio の起動
Mastra Studio は開発サーバとしてローカルに起動でき、bun run dev でサーバを立ち上げます:
bun run dev
起動後は Studio UI にアクセスし、エージェントやワークフローを実行したり REST API を試すことができます:
| URL | 用途 |
|---|---|
http://localhost:<PORT>/ |
Studio UI |
http://localhost:<PORT>/api |
Swagger UI(API ドキュメント) |
最初の時点で Mastra のサンプルとして、天気に関するエージェントやワークフローが存在しています。
※bun create mastra したときに登録されるエージェントは上記画像と異なります。
Mastra でツールとエージェントを定義する
サンプルとして使用するエージェントを作成していきます。
ツール定義
まずは、都市名を受け取り現在時刻を返すツールを作成します。Mastra のツールは createTool 関数を使って定義します。
// src/mastra/tools/getTime.ts import { createTool } from '@mastra/core/tools'; import { z } from 'zod'; // 対応都市とタイムゾーンのマッピング const SUPPORTED_CITIES: Record<string, string> = { 'Tokyo': 'Asia/Tokyo', 'Paris': 'Europe/Paris', 'New York': 'America/New_York', 'London': 'Europe/London', 'Sydney': 'Australia/Sydney', 'Dubai': 'Asia/Dubai', 'Los Angeles': 'America/Los_Angeles', 'Singapore': 'Asia/Singapore', 'Beijing': 'Asia/Shanghai', 'Moscow': 'Europe/Moscow', }; const SUPPORTED_CITIES_LIST = [ 'Tokyo', 'Paris', 'New York', 'London', 'Sydney', 'Dubai', 'Los Angeles', 'Singapore', 'Beijing', 'Moscow', ]; export const getTimeTool = createTool({ id: 'getTime', description: `都市名を受け取り、現在時刻を返します。対応都市: ${SUPPORTED_CITIES_LIST.join(', ')}`, inputSchema: z.object({ city: z.string() }), outputSchema: z.object({ time: z.string(), city: z.string(), timezone: z.string() }), execute: async ({ context }) => { const { city } = context; const timezone = SUPPORTED_CITIES[city]; if (!timezone) { throw new Error( `「${city}」は対応していない都市です。対応都市: ${SUPPORTED_CITIES_LIST.join(', ')}` ); } const now = new Date(); const time = now.toLocaleString('ja-JP', { timeZone: timezone, year: 'numeric', month: '2-digit', day: '2-digit', hour: '2-digit', minute: '2-digit', second: '2-digit', }); return { time, city, timezone }; }, });
ポイント:
inputSchema/outputSchemaで Zod スキーマを使って入出力の型を定義descriptionは LLM がツールを選択する際に参照するため、明確に記述するexecute関数で実際の処理を実装
Agent 定義
次に、LLM モデルとツールを統合したエージェントを定義します。
// src/mastra/agents/timeAgent.ts import { Agent } from '@mastra/core/agent'; import { getTimeTool } from '../tools/getTime'; export const timeAgent = new Agent({ name: 'timeAgent', instructions: `ユーザーから時刻について聞かれたときはツールを利用して時刻を取得してください。そうでない場合はアシスタントとしてユーザーのためになるように適切に対応してください。`, model: 'openai/gpt-5-nano', tools: { getTime: getTimeTool }, });
ポイント:
instructionsでエージェントの振る舞いを自然言語で指示toolsでエージェントが利用できるツールを登録modelで使用する LLM モデルを指定(Vercel AI SDK の形式)
Mastra への登録
index.ts にエージェントを追加することで、Studio 上の管理画面でエージェントが確認できるようになります。
// src/mastra/index.ts import { Mastra } from '@mastra/core/mastra'; import { timeAgent } from './agents/timeAgent'; export const mastra = new Mastra({ agents: { timeAgent }, });
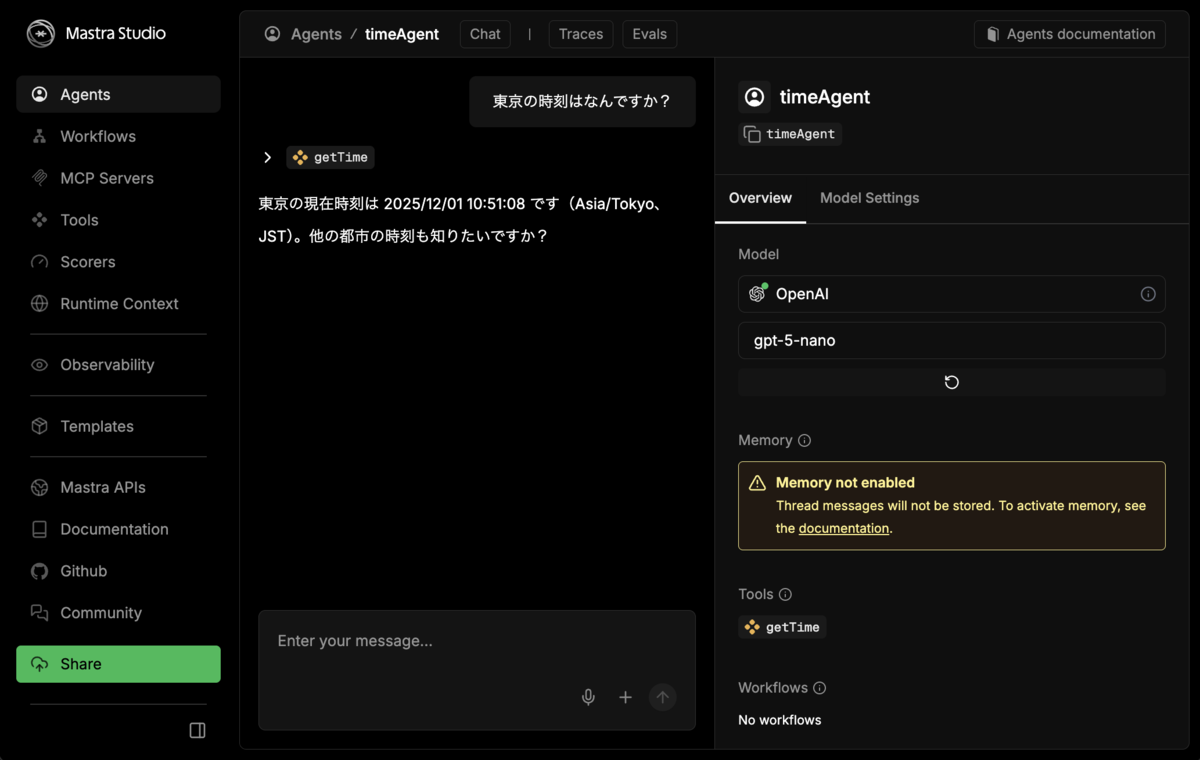
動作確認
このエージェントは Mastra Studio から GUI でメッセージを送信してテストできます。本格的な TypeScript でのテストを作成する前のデバッグ実行を簡単に行えます。
また、API 経由でもエージェントを呼び出すことができます:
curl http://localhost:4111/api/agents/timeAgent/generate \
-H 'Content-Type: application/json' \
-d '{"messages": [{"role":"user","content":"東京の現在時刻は?"}]}'
出力は、中間ステップやツール呼び出し、最終出力を含む以下のような JSON が返されます:
{ "text": "東京の現在時刻は、2025年12月01日 12:07:18です。", "usage": {...}, "steps": [...], "finishReason": "stop", "toolCalls": [...], "toolResults": [...], ... }
Langfuse でデータセットを作成
Langfuse プロジェクトの準備
Langfuse のデータセットは、入力と期待出力のペアを集めたコレクションです。データセットは Langfuse UI または SDK から作成できます。
まず、Langfuse で Organization / Project をそれぞれ新規に作成します。
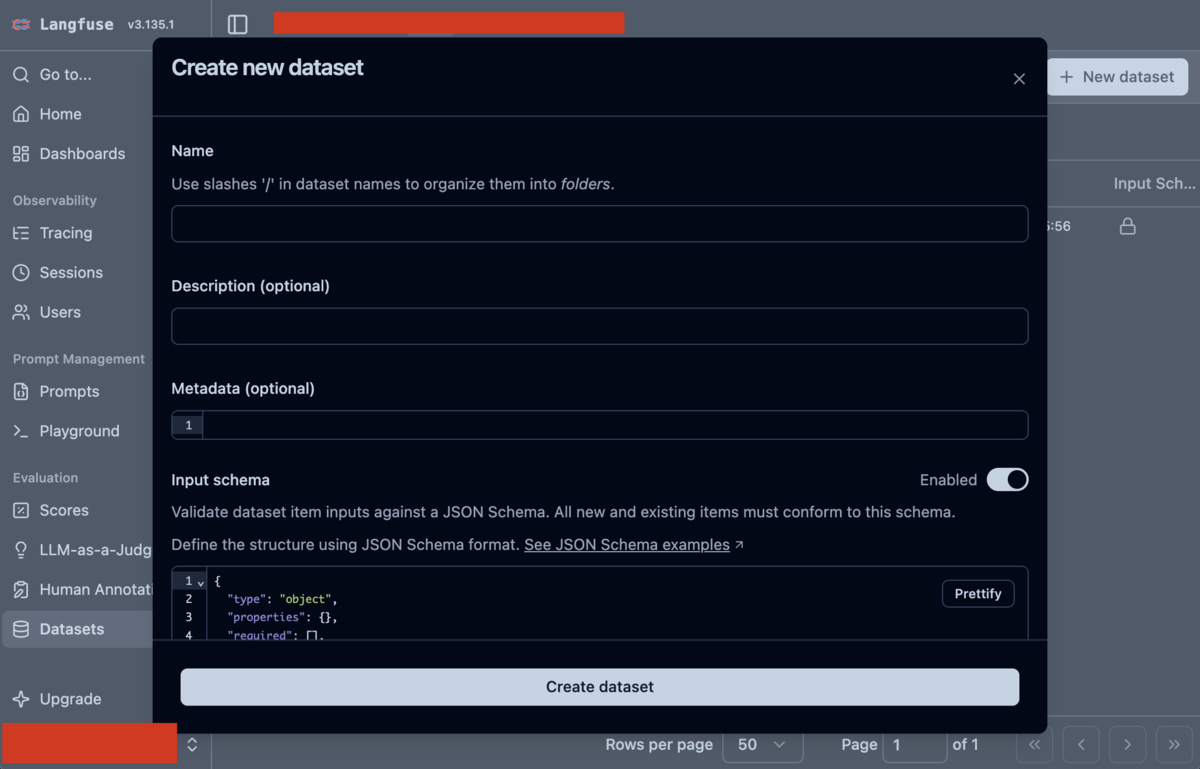
データセットの作成
プロジェクトのページに行き、左側のメニューから Datasets をクリックし、データセットのページで + New dataset をクリックしてデータセットを作成します。
データセット名は evaluation-test とします。
スキーマの定義
データセット作成時に input と output のスキーマを指定できるので、下記のように指定します。
一般的には output には期待される出力テキストのサンプルを入れることが多いですが、今回はサンプルとしてツールコールの正確性を検証します。そのため、ツールコールの情報のみを output に含めます。
Input スキーマ:
{ "type": "object", "properties": { "prompt": { "type": "string", "description": "ユーザーからの質問文" } }, "required": ["prompt"], "additionalProperties": false }
Output スキーマ:
{ "type": "object", "properties": { "tool_calls": { "type": "array", "description": "期待されるツール呼び出しのリスト", "items": { "type": "object", "properties": { "tool_name": { "type": "string", "description": "呼び出されるツール名" }, "parameters": { "type": "object", "description": "ツールに渡されるパラメータ" } }, "required": ["tool_name"] } }, "expected_tool_call_count": { "type": "integer", "description": "期待されるツール呼び出し回数", "minimum": 0 } }, "required": ["tool_calls", "expected_tool_call_count"], "additionalProperties": false }
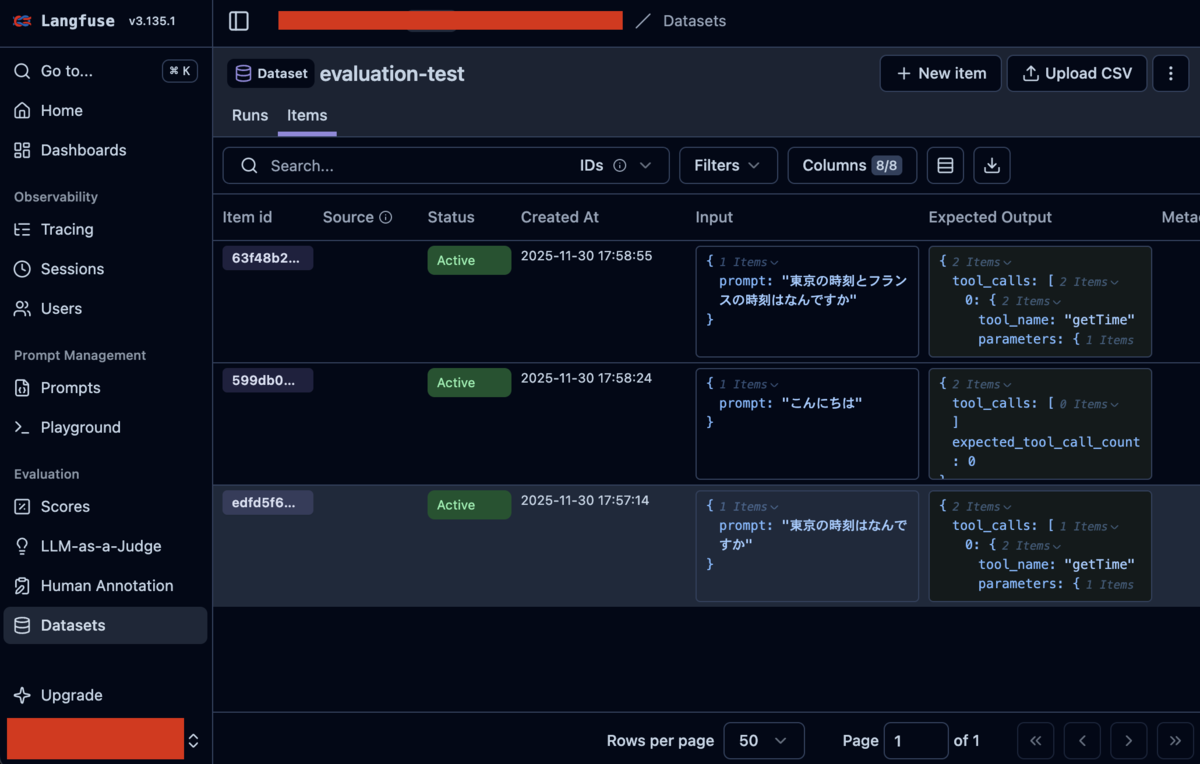
データセットアイテムの追加
サンプルとして下記のアイテムを追加していきます。
アイテム 1: 単一都市の時刻を聞く質問(ツールを1回呼ぶべき)
Input:
{ "prompt": "東京の時刻はなんですか" }
Expected Output:
{ "tool_calls": [ { "tool_name": "getTime", "parameters": { "city": "Tokyo" } } ], "expected_tool_call_count": 1 }
アイテム 2: 時刻に関係ない挨拶(ツールを呼ばないべき)
Input:
{ "prompt": "こんにちは" }
Expected Output:
{ "tool_calls": [], "expected_tool_call_count": 0 }
アイテム 3: 複数都市の時刻を聞く質問(ツールを2回呼ぶべき)
Input:
{ "prompt": "東京の時刻とフランスの時刻はなんですか" }
Expected Output:
{ "tool_calls": [ { "tool_name": "getTime", "parameters": { "city": "Tokyo" } }, { "tool_name": "getTime", "parameters": { "city": "Paris" } } ], "expected_tool_call_count": 2 }
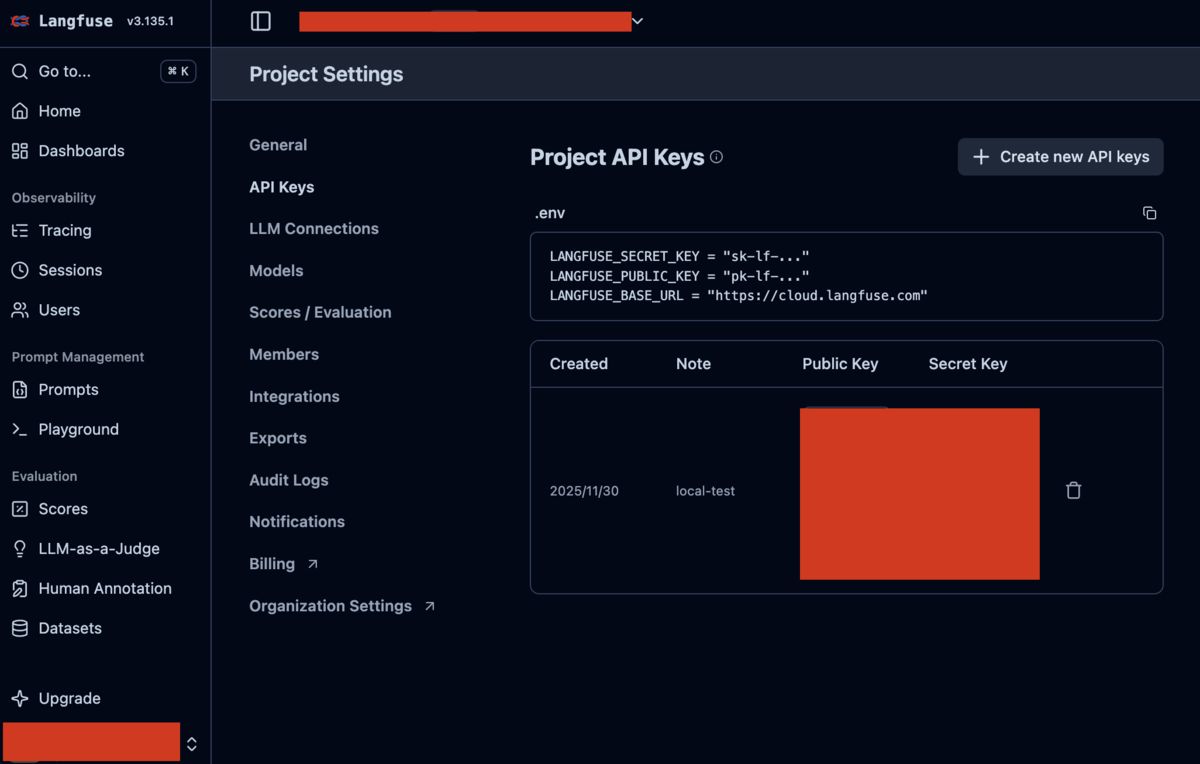
API キーの設定
コードから Langfuse にアクセスできるように、設定から API キーを作成し、リポジトリの .env に保存します。
# OpenAI API Key (Mastraで使用: 対話形式のセットアップで設定される) OPENAI_API_KEY=sk-... # Langfuse設定 LANGFUSE_SECRET_KEY=sk-lf-... LANGFUSE_PUBLIC_KEY=pk-lf-... LANGFUSE_BASE_URL=https://cloud.langfuse.com
APIキーはSettingsから作成することができます。
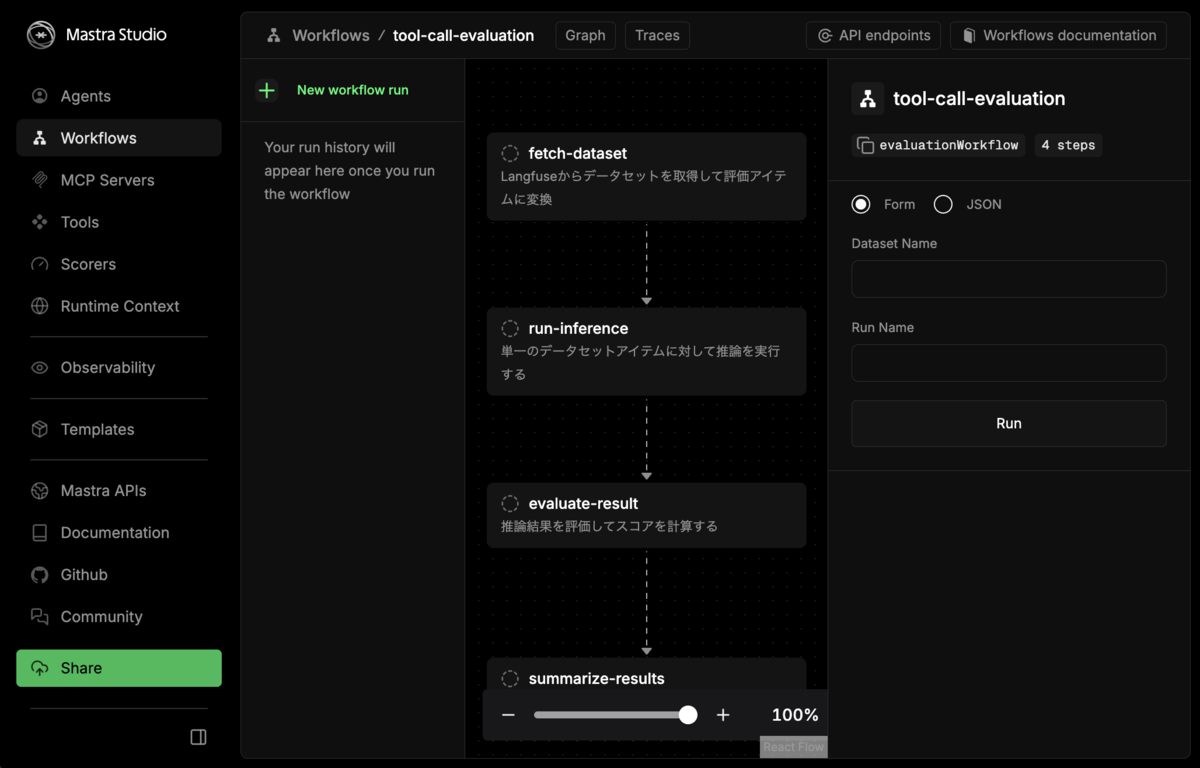
精度検証ワークフローの作成
Langfuse からデータを取得し、各アイテムに対して推論を行い、評価値を Langfuse に戻す処理を、Mastra のワークフローとして組みます。MLOps の文脈では、モデルの訓練や精度評価をパイプラインとして実装して再現性を持たせますが、それに近いイメージです。
ワークフローの全体像
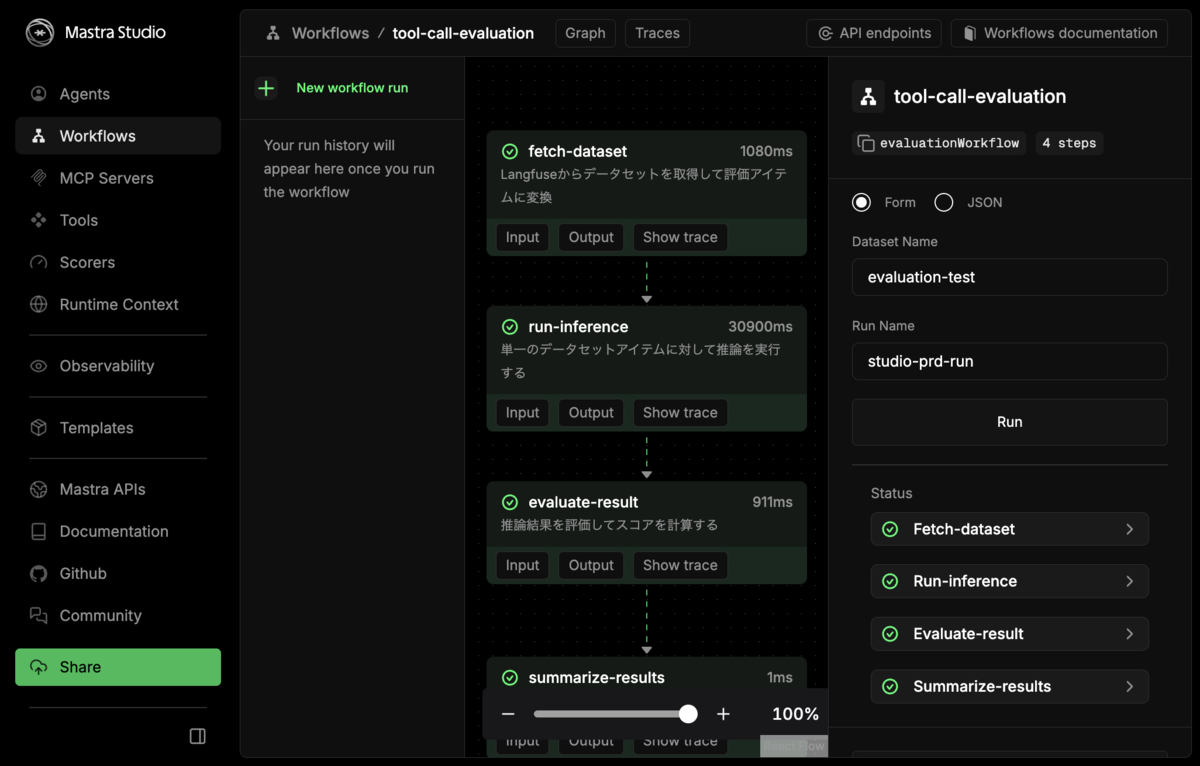
ワークフローは以下の4つのステップで構成されます:
- fetch-dataset: Langfuse からデータセットを取得
- run-inference: 各アイテムに対して推論を実行(foreach で並列処理)
- evaluate-result: 推論結果を評価してスコアを計算(foreach で並列処理)
- summarize-results: 結果をまとめてサマリーを出力
パッケージのインストール
ワークフローに必要なパッケージを追加します。package.json を以下のように更新してください:
{ "name": "mastra-langfuse-demo", "module": "index.ts", "type": "module", "private": true, "devDependencies": { "@types/bun": "latest", "mastra": "^0.18.6" }, "peerDependencies": { "typescript": "^5.9.3" }, "engines": { "node": ">=22.13.0" }, "scripts": { "dev": "mastra dev", "build": "mastra build", "start": "mastra start" }, "dependencies": { "@langfuse/client": "^4.4.2", "@langfuse/otel": "^4.4.2", "@langfuse/tracing": "^4.4.2", "@mastra/core": "^0.24.6", "@mastra/evals": "^0.14.4", "@mastra/libsql": "^0.16.3", "@mastra/loggers": "^0.10.19", "@mastra/memory": "^0.15.12", "@opentelemetry/sdk-node": "^0.208.0", "@opentelemetry/sdk-trace-node": "^2.2.0", "@types/node": "^24.10.1", "langfuse": "^3.38.6", "zod": "^4" } }
インストールを実行します:
bun install
ワークフローの実装
以下のファイルを作成します:
// src/mastra/workflows/evaluation-workflow.ts import { createWorkflow, createStep } from '@mastra/core/workflows'; import { z } from 'zod'; import { LangfuseClient } from '@langfuse/client'; import { startActiveObservation, createTraceId, setLangfuseTracerProvider } from '@langfuse/tracing'; import { NodeTracerProvider } from '@opentelemetry/sdk-trace-node'; import { LangfuseSpanProcessor } from '@langfuse/otel'; import { timeAgent } from '../agents/timeAgent'; // =========================================== // OpenTelemetry + Langfuse の設定 // =========================================== // LangfuseSpanProcessorを作成 (forceFlush用に保持) const langfuseSpanProcessor = new LangfuseSpanProcessor({ publicKey: process.env.LANGFUSE_PUBLIC_KEY!, secretKey: process.env.LANGFUSE_SECRET_KEY!, baseUrl: process.env.LANGFUSE_BASE_URL ?? 'https://cloud.langfuse.com', }); // Langfuse専用の分離されたTracerProviderを作成 (Mastra StudioのOTEL設定と競合しない) const langfuseTracerProvider = new NodeTracerProvider({ spanProcessors: [langfuseSpanProcessor], }); // Langfuse用のTracerProviderを登録 (グローバルではなくLangfuse専用) setLangfuseTracerProvider(langfuseTracerProvider); // Langfuseクライアントの初期化 (データセット操作・スコア記録用) const langfuse = new LangfuseClient({ secretKey: process.env.LANGFUSE_SECRET_KEY, publicKey: process.env.LANGFUSE_PUBLIC_KEY, baseUrl: process.env.LANGFUSE_BASE_URL, }); // =========================================== // スキーマ定義 // =========================================== // 評価アイテムのスキーマ const evaluationItemSchema = z.object({ itemId: z.string(), prompt: z.string(), expectedToolCalls: z.array( z.object({ tool_name: z.string(), parameters: z.record(z.string(), z.unknown()).optional(), }) ), expectedToolCallCount: z.number(), datasetName: z.string(), runName: z.string(), }); // 推論結果のスキーマ (Step 2の出力、Step 3の入力) const inferenceResultSchema = z.object({ itemId: z.string(), prompt: z.string(), expectedToolCalls: z.array( z.object({ tool_name: z.string(), parameters: z.record(z.string(), z.unknown()).optional(), }) ), expectedToolCallCount: z.number(), datasetName: z.string(), runName: z.string(), // 推論結果 responseText: z.string(), actualToolCalls: z.array( z.object({ toolName: z.string(), parameters: z.record(z.string(), z.unknown()).optional(), }) ), toolResults: z.array(z.unknown()), // トレース情報 traceId: z.string(), }); // 評価結果のスキーマ const evaluationResultSchema = z.object({ itemId: z.string(), prompt: z.string(), expectedToolCallCount: z.number(), actualToolCallCount: z.number(), isCorrectCount: z.boolean(), isCorrectTools: z.boolean(), score: z.number(), }); // データセットアイテムを保持するためのMap (item.link用) // 本番環境ではワークフローの実行毎に作成して干渉しないようにするべき let datasetItemsMap: Map<string, any> = new Map(); // =========================================== // Step 1: Langfuseからデータセットを取得 // =========================================== const fetchDatasetStep = createStep({ id: 'fetch-dataset', description: 'Langfuseからデータセットを取得して評価アイテムに変換', inputSchema: z.object({ datasetName: z.string(), runName: z.string(), }), outputSchema: z.array(evaluationItemSchema), execute: async ({ inputData }) => { const { datasetName, runName } = inputData; console.log(`Fetching dataset: ${datasetName}`); const dataset = await langfuse.dataset.get(datasetName); console.log(`Found ${dataset.items.length} items`); // データセットアイテムを保持 (後でitem.linkに使用) datasetItemsMap.clear(); for (const item of dataset.items) { datasetItemsMap.set(item.id, item); } const items = dataset.items.map((item) => { const input = item.input as { prompt: string }; const expectedOutput = item.expectedOutput as { tool_calls: { tool_name: string; parameters?: Record<string, any> }[]; expected_tool_call_count: number; }; return { itemId: item.id, prompt: input.prompt, expectedToolCalls: expectedOutput.tool_calls, expectedToolCallCount: expectedOutput.expected_tool_call_count, datasetName, runName, }; }); return items; }, }); // =========================================== // Step 2: 各アイテムに対して推論を実行 (foreachで呼ばれる) // =========================================== const runInferenceStep = createStep({ id: 'run-inference', description: '単一のデータセットアイテムに対して推論を実行する', inputSchema: evaluationItemSchema, outputSchema: inferenceResultSchema, execute: async ({ inputData }) => { const { itemId, prompt, expectedToolCalls, expectedToolCallCount, datasetName, runName } = inputData; console.log(`\n--- Running inference: ${prompt} ---`); // 各評価ごとに新しいtraceIdを生成 const traceId = await createTraceId(`evaluation-${itemId}-${runName}`); // startActiveObservationでトレースを作成し、コールバック内で推論を実行 const [span, actualToolCalls, toolResults, responseText] = await startActiveObservation( `evaluation-${itemId}`, async (span) => { // timeAgentで推論実行 const response = await timeAgent.generate(prompt); // ツールコールの抽出 const actualToolCalls: { toolName: string; parameters?: Record<string, unknown> }[] = []; const toolResults: unknown[] = []; if (response.toolCalls && response.toolCalls.length > 0) { for (const toolCall of response.toolCalls) { actualToolCalls.push({ toolName: toolCall.payload.toolName, parameters: toolCall.payload.args as Record<string, unknown> | undefined, }); } } // toolResultsの抽出 if (response.toolResults && response.toolResults.length > 0) { for (const result of response.toolResults) { toolResults.push(result.payload.result); } } // outputをトレースに記録 span.update({ input: { prompt }, output: { text: response.text, toolCalls: actualToolCalls, toolResults: toolResults, }, metadata: { datasetName, runName, itemId, }, }); // データセットアイテムにトレースをリンク const datasetItem = datasetItemsMap.get(itemId); if (datasetItem) { await datasetItem.link(span, runName, { description: 'Tool call evaluation', metadata: { model: 'gpt-4o-mini' }, }); } return [span, actualToolCalls, toolResults, response.text] as const; }, { asType: 'span', parentSpanContext: { traceId: traceId, spanId: '0000000000000000', traceFlags: 1, }, } ); // スパンを確実に送信するためにflush (OpenTelemetry側) await langfuseSpanProcessor.forceFlush(); console.log(`Inference completed. Tool calls: ${actualToolCalls.length}`); return { itemId, prompt, expectedToolCalls, expectedToolCallCount, datasetName, runName, responseText, actualToolCalls, toolResults, traceId: span.traceId, }; }, }); // =========================================== // Step 3: 推論結果を評価 (foreachで呼ばれる) // =========================================== const evaluateResultStep = createStep({ id: 'evaluate-result', description: '推論結果を評価してスコアを計算する', inputSchema: inferenceResultSchema, outputSchema: evaluationResultSchema, execute: async ({ inputData }) => { const { itemId, prompt, expectedToolCalls, expectedToolCallCount, actualToolCalls, traceId, } = inputData; console.log(`\n--- Evaluating result: ${prompt} ---`); const actualToolCallCount = actualToolCalls.length; // 評価: ツールコール回数が一致しているか const isCorrectCount = actualToolCallCount === expectedToolCallCount; // 評価: ツール名とパラメータが一致しているか let isCorrectTools = true; if (expectedToolCalls.length > 0) { // ツールコールをJSON文字列化してソート可能にする const serializeToolCall = (toolName: string, params?: Record<string, unknown>) => { const sortedParams = params ? Object.keys(params).sort().reduce((acc, key) => { acc[key] = params[key]; return acc; }, {} as Record<string, unknown>) : {}; return JSON.stringify({ toolName, parameters: sortedParams }); }; const expectedSerialized = expectedToolCalls .map((tc) => serializeToolCall(tc.tool_name, tc.parameters as Record<string, unknown> | undefined)) .sort(); const actualSerialized = actualToolCalls .map((tc) => serializeToolCall(tc.toolName, tc.parameters)) .sort(); isCorrectTools = expectedSerialized.length === actualSerialized.length && expectedSerialized.every((serialized, i) => serialized === actualSerialized[i]); } else { isCorrectTools = actualToolCallCount === 0; } // スコア計算 const score = isCorrectCount && isCorrectTools ? 1.0 : isCorrectCount || isCorrectTools ? 0.5 : 0.0; console.log(`Expected: ${expectedToolCallCount}, Actual: ${actualToolCallCount}, Score: ${score}`); // スコアを記録 await langfuse.score.create({ traceId: traceId, name: 'tool_call_accuracy', value: score, comment: `Count: ${isCorrectCount ? 'correct' : 'incorrect'} (expected: ${expectedToolCallCount}, actual: ${actualToolCallCount}), Tools+Params: ${isCorrectTools ? 'correct' : 'incorrect'}`, }); await langfuse.flush(); return { itemId, prompt, expectedToolCallCount, actualToolCallCount, isCorrectCount, isCorrectTools, score, }; }, }); // =========================================== // Step 4: 結果をまとめる // =========================================== const summarizeStep = createStep({ id: 'summarize-results', description: '評価結果をまとめてサマリーを出力', inputSchema: z.array(evaluationResultSchema), outputSchema: z.object({ totalItems: z.number(), averageScore: z.number(), passedCount: z.number(), failedCount: z.number(), results: z.array(evaluationResultSchema), }), execute: async ({ inputData: results }) => { const totalItems = results.length; const averageScore = totalItems > 0 ? results.reduce((sum, r) => sum + r.score, 0) / totalItems : 0; const passedCount = results.filter((r) => r.score === 1.0).length; const failedCount = totalItems - passedCount; console.log(`\n=== Summary ===`); console.log(`Total: ${totalItems}, Avg Score: ${averageScore.toFixed(2)}, Passed: ${passedCount}, Failed: ${failedCount}`); // TracerProviderをフラッシュ await langfuseSpanProcessor.forceFlush(); console.log('Traces sent to Langfuse.'); return { totalItems, averageScore, passedCount, failedCount, results, }; }, }); // =========================================== // ワークフロー定義 // =========================================== export const evaluationWorkflow = createWorkflow({ id: 'tool-call-evaluation', description: 'ツールコールの正確性を評価するワークフロー', inputSchema: z.object({ datasetName: z.string(), runName: z.string(), }), outputSchema: z.object({ totalItems: z.number(), averageScore: z.number(), passedCount: z.number(), failedCount: z.number(), results: z.array(evaluationResultSchema), }), }) .then(fetchDatasetStep) .foreach(runInferenceStep) .foreach(evaluateResultStep) .then(summarizeStep) .commit();
ワークフローの登録
作成したワークフローを src/mastra/index.ts に登録します:
// src/mastra/index.ts import { Mastra } from '@mastra/core/mastra'; import { timeAgent } from './agents/timeAgent'; import { evaluationWorkflow } from './workflows/evaluation-workflow'; export const mastra = new Mastra({ agents: { timeAgent }, workflows: { evaluationWorkflow }, });
これにより、Studio 上でもワークフローを確認・実行できるようになります。
精度検証ワークフローの実行
実行スクリプトの作成
ワークフローを実行するためのスクリプトを作成します:
// src/run-evaluation-workflow.ts import { mastra } from './mastra'; async function runEvaluationWithWorkflow(datasetName: string, runName: string) { console.log(`\n=== Evaluation Start (Mastra Workflow) ===`); console.log(`Dataset: ${datasetName}`); console.log(`Run: ${runName}\n`); // ワークフローを取得して実行 const workflow = mastra.getWorkflow('evaluationWorkflow'); const run = await workflow.createRunAsync(); const result = await run.start({ inputData: { datasetName, runName, }, }); if (result.status === 'success') { console.log('\n=== Final Result ==='); console.log(JSON.stringify(result.result, null, 2)); return result.result; } else { console.error('Workflow failed:', result); throw new Error('Workflow execution failed'); } } // 実行 const datasetName = process.argv[2] || 'evaluation-test'; const runName = process.argv[3] || `workflow-run-${Date.now()}`; runEvaluationWithWorkflow(datasetName, runName) .then((result) => { console.log('\nEvaluation completed successfully!'); const typedResult = result as { failedCount: number }; process.exit(typedResult.failedCount > 0 ? 1 : 0); }) .catch((error) => { console.error('Evaluation failed:', error); process.exit(1); });
ワークフローの実行
以下のコマンドでワークフローを実行します:
bun src/run-evaluation-workflow.ts evaluation-test my-run-name
Mastra Studio からの実行
ワークフローは Mastra Studio の UI からも実行できます。bun run dev で Studio を起動し、Workflows セクションから tool-call-evaluation を選択して実行できます。
Langfuse での結果確認
実行後に、Langfuse の Dataset 画面を確認することで、Evaluation の結果を見ることができます。
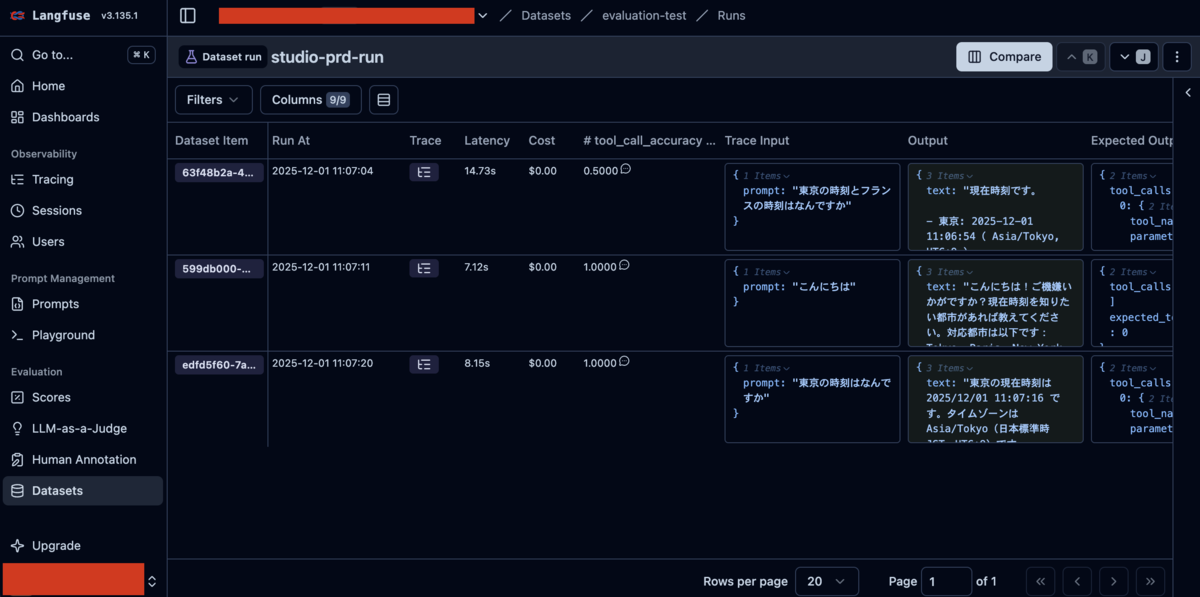
各データセットアイテムに対して:
- トレースがリンクされている
- スコア(tool_call_accuracy)が記録されている
- 入力・出力・メタデータが保存されている
これにより、本番運用の Agent のコードに対して再現性を持ってワークフローによる精度評価を行うことができます。
まとめと次のステップ
本記事では、Mastra でツール呼び出しを含むエージェントを構築し、Langfuse を使ってツール呼び出しの正確性を評価する手順を紹介しました。Mastra と Langfuse を組み合わせることで、エージェント開発の「構築」と「評価」のサイクルを効率化し、信頼性の高い生成 AI アプリケーションを継続的に改善できます。
本記事で実現したこと
- Mastra でのエージェント構築: ツールを持つエージェントを定義し、Studio で動作確認
- Langfuse でのデータセット管理: 入力と期待出力のペアをデータセットとして管理
- 評価ワークフローの構築: Mastra のワークフロー機能で再現性のある評価パイプラインを実装
今後の発展
以下のような発展も考えられます:
- バージョン管理: エージェントやプロンプトのバージョン管理と、バージョン間での精度比較
- コードの再利用: 本番のコードと精度検証のコードをなるべく共通化する
- 高度な評価指標: LLM-as-a-judge など、ツールコールだけでなくアウトプットの品質を LLM で評価
- 自動訓練パイプライン: プロンプトの自動最適化と、訓練・評価パイプラインの統合
- CI/CD 連携: GitHub Actions などでの評価の自動化
今回はMastra workflowを利用して精度評価パイプラインを構築しましたが、Langfuseにもwebhook経由で実験を実行する機能があるので、そちらに合わせて設計することもできるかもしれません。
ミツモアで一緒に働きませんか?
ミツモアでは、 生成AIを活用して圧倒的な生産性を生み出し、日本のGDPを向上させる という目標に向けて、一緒に働く仲間を募集しています。
今回ご紹介したように、 MastraやLangfuseなどを活用したAgentOps環境の構築と、プロダクトへの組み込み を急ピッチで推進しています。
少しでも興味をお持ちの方は、カジュアル面談からでも大歓迎です。ぜひお気軽にご応募ください!
ミツモア採用ページ: https://corp.meetsmore.com/