※こちらはミツモアAdvent Calendar 2023の19日目の記事です。
ミツモアのデータチームに6月から参画している赤藤と申します。主にデータ基盤の運用、データ加工、可視化を行なっています。
ミツモアではBIツールとしてRedashを使用しており、RedashをPythonで実行したいケースがあったのですが、そういった記事が世の中にあまり無さそうでしたのでご紹介させて頂きます。
Redashとは
まずRedashについて簡単にご説明させて頂きます。 Redashは複数のデータソースに接続し、Redash上で直接SQLが実行ができるBIツールのひとつで、以下のようにデータの作成、可視化を容易に行うことができます。利用者が自由に変更できるパラメータ機能もあり、動的にデータを出力することができます。
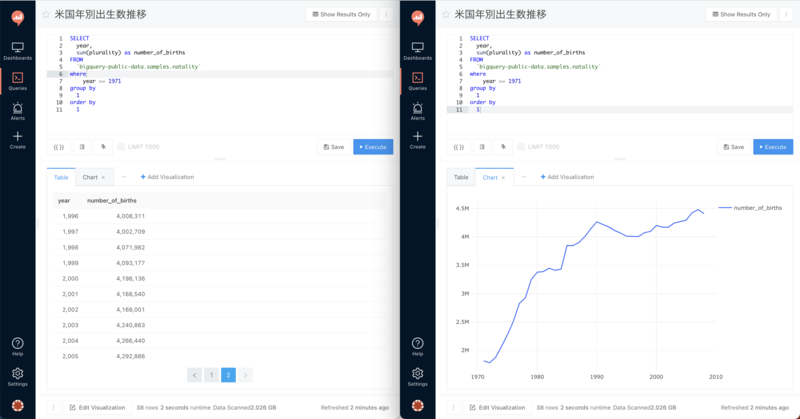
実行コード
SQLは実行速度も速くデータの抽出/加工に向いていますが、一方でPythonのような柔軟性は無いのでPythonと組み合わせて使用することで様々な事例に活用することができます。 この記事では関数の紹介を目的としているため簡易的な例を記載しますが、実務ではこの関数を使用しつつGoogle Spread Sheetを参照することで xmlファイルを自動で作成するようにしました。今まで手作業で行っていた事務作業を自動化し、0.25h×ファイル数の工数を削減することができました。
設定 必要なライブラリのimportとパラメータを設定します。
import requests #redashURL redash_host = "https://XXX.com" api_key = "XXX" query_id = NAPIキーは以下の画面から確認することができます。
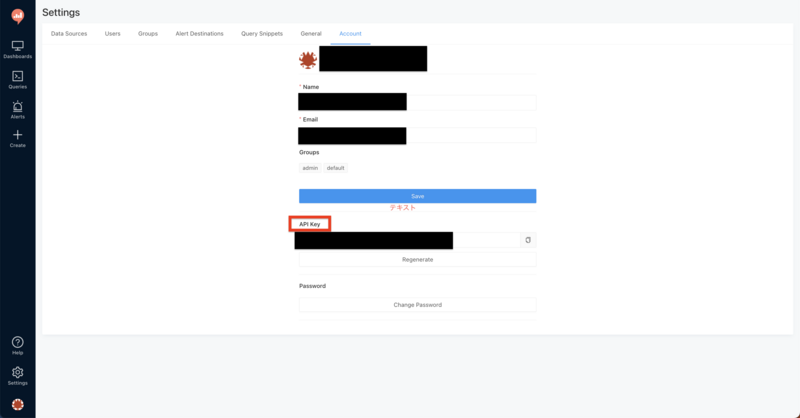
query_idは作成したクエリに一意に付与されるIDで、以下のようにURLから確認することができます。

関数定義 Redashを実行する関数を作成します。
def get_redash(query_id): url = f"{redash_host}/api/queries/{query_id}/refresh" headers = {"Authorization": f"Key {api_key}"} #クエリ実行 response = requests.post(url, headers = headers) #redashの更新を待つ time.sleep(60) result_url = f"{redash_host}/api/queries/{query_id}/results.json" #クエリ実行結果を取得 latest_response = requests.get(result_url, headers = headers) #クエリ実行結果からデータを取得 results = latest_response.json()["query_result"]["data"]["rows"] #DataFrameに格納 _df = pd.DataFrame(results) return _df※
time.sleep(60)が実はかなり大事で、SQLが回っている時間を考慮せずに結果を取得すると、前回更新時の古いデータを取得することになってしまい、今回実行した欲しいデータが取得できません。実行するSQLの重さに合わせて待ち時間を設定する必要があります。
実行結果
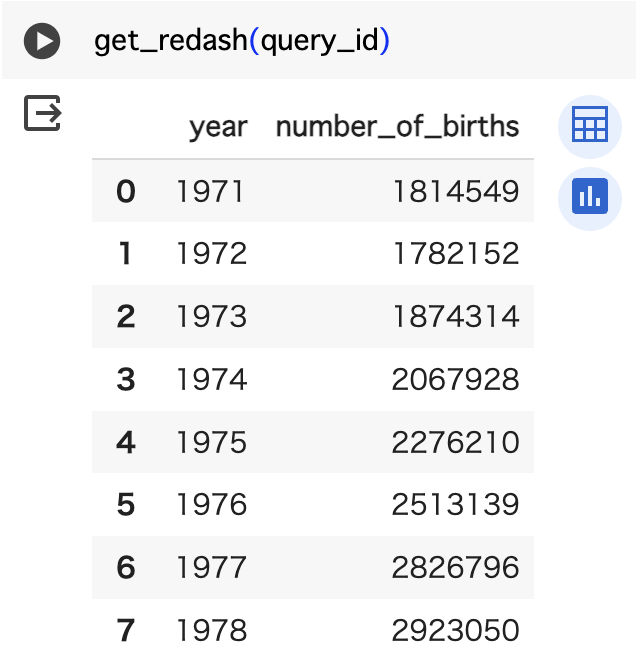
小噺
PythonでSQLを実行したことのある方は、「わざわざRedash介さなくても直接BigQueryやRed Shfitに接続してSQL実行すれば良いのでは?」と思われたかもしれません。その問いに対する答えは「その通り。」です。ただし、組織単位で運用している都合上権限の問題もあり、Pythonコード(今回はGoogle Colabolatoryを使用)を使い回す上でRedashを介す必要があったため、このような処理にしてあります。こういった事情からPythonでRedashを実行する記事はあまり出回っていないのかもしれません。
今回Redashを介するような設計にした理由
「小噺」で触れたように直接BigQuery等へ接続すれば良いのですが、BigQueryのようなDWH(データウェアハウス)へのアクセスをエンジニア部門やデータ部門に制限し、ビジネス側の部門はデータにアクセスできないような権限管理をしている組織も多いのではないでしょうか? 今回の実装はデータ部門に所属する私ではなく、ビジネス部門の方が必要な時に自身で実行しxmlファイルを取得するような運用を想定していたため、BigQueryにアクセスできない人でもPythonを通じてSQLを実行できるような設計にしました。
Redashを介さずに済ませるには?
BigQeuryへのアクセスを解放すればこのようにわざわざRedashを介す必要はないですが、データ知識のない部署にまで権限を付与するのは難しいでしょう。そういった観点ではデータ知識の普及・民主化が必要です。ビジネス側のデータ理解が深まればよりスピーディに分析が進むでしょうし、データ部門とのコミュニケーションも円滑に進むようになるのではないでしょうか。現にミツモアでもデータの民主化を進めております!
そんなミツモアでは様々な職種のエンジニアを積極的に採用しています。ぜひチェックしてみてください!!
採用ページ: https://meetsmore.com/company/recruit 募集要項: https://herp.careers/v1/meetsmore/3cQ_H41s6tZu